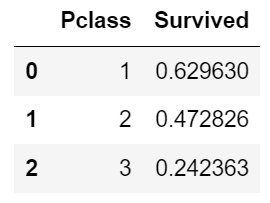
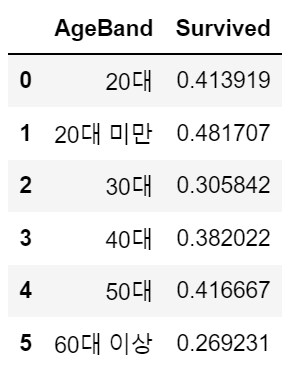
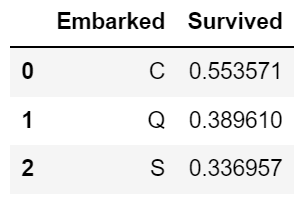
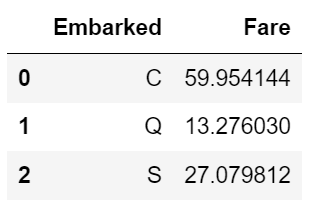
info) 정규세션 1주차 Pandas 실습 (World_2012 데이터 사용)
1. 데이터 확인
1-1. 데이터 불러오기
import pandas as pd
import numpy as np
df = pd.read_excel('./World_2012.xlsx')
df1-2. 데이터 형태 확인
df.head(3) #상위 3개 확인
#df.tail() #하위 5개 확인1-3. 데이터 크기 확인
df.shape #(행,열) 크기 확인1-4. 데이터의 결측치 확인
df.isna().sum()1-5. ‘Continent’ 컬럼의 고유값 확인
df['Continent'].unique()2. 결측치 처리
2-1. GDP 결측치 처리
- 대륙별 GDP 평균을 구하여 결측치에 대체
#{Continent : GDP평균} dictionary 생성
gdp_avg = dict(df.groupby('Continent')['GDP'].mean())
#해당 continent와 GDP가 null인 값에 대해 대륙별 GDP평균으로 대체
for (continent, gdp) in gdp_avg.items():
df.loc[(df['Continent'] == continent) & (df['GDP'].isnull()), 'GDP'] = gdp
#결측치 재확인
df['GDP'].isna().sum()2-2. 나머지 결측치도 동일한 방식으로 처리
- 함수를 정의하여 결측치가 있는 모든 컬럼에 적용
#대륙별 feature들의 평균값 확인
df.groupby('Continent').mean()
#대륙별 평균값으로 결측치를 대체하는 함수 정의
def fillwithAverage(x):
continent_avg = dict(df.groupby('Continent')[x].mean())
for i in continent_avg.keys():
df.loc[(df['Continent'] == i) & (df[x].isnull()), x] = continent_avg[i]
column_list =list(df.columns) #feature 목록 리스트
#GDP를 비롯한 Country, Continent, Population은 제외
remove_list = ['Country', 'Continent', 'Population', 'GDP']
column_list = [col for col in column_list if col not in remove_list]
print(column_list)
#반복문을 통해 함수 적용
for col in column_list:
fillwithAverage(col)
#결측치 재확인
df.isna().sum()3. 파생변수 생성
3-1. 1인당 GDP 소득인 'PCI'라는 파생변수 생성
- GDP 와 Population 활용
df['PCI'] = df['GDP'] / df['Population']
df.head(3)3-2. 기대수명인 'Life Expectancy'라는 파생변수 생성
- Male Life Expectancy, Femal Life Expectancy 두 feature의 평균 활용
df['Life Expectancy'] = (df['Male Life Expectancy'] + df['Femal Life Expectancy']) / 2
df.tail(2)4. 유럽 데이터 생성
4-1. 'Continet' 컬럼에서 '유럽'에 해당하는 것만 필터링하여 europe_data에 저장
- loc 함수 사용
europe_data = df.loc[df['Continent'] == '유럽', :]
europe_data.head(3)4-2. europe_data의 Population이 10,000,000이상인 나라만 필터링하여 europe_data 갱신
europe_data = europe_data[europe_data.Population >= 10000000]
europe_data.head(3)4-3. europe_data에서 PCI(1인당 소득) 기준 상위 3개 국가 확인
europe_data.sort_values('PCI', ascending = False)[:3]4-4. europe_data에서 PCI(1인당 소득)가 가장 작은 국가 확인
europe_data.sort_values('PCI', ascending = True)[:1]5. 선진국 데이터 생성
5-1. Population이 10,000,000이상이고 PCI가 30,000이상인 국가를 필터링하여 developed_data라는 변수에 저장
developed_data = df.loc[(df['Population'] >= 10000000) & (df['PCI'] >= 30000),:]
developed_data5-2. developed_data에서 Business TR이 0.3이하 이거나, Internet이 0.8 이상인 국가를 필터링
- Column은 Country Business, TR Loan, IR만 표시
developed_data.loc[(developed_data['Business TR'] <= 0.3) | (developed_data['Internet'] >= 0.8),:][['Country', 'Business TR', 'Loan IR']]
'BACS > 정규세션' 카테고리의 다른 글
| [BACS] 정규 세션 2주차 Titanic 시각화 (2) (0) | 2022.11.04 |
|---|---|
| [BACS] 정규 세션 2주차 Titanic 시각화 (1) (0) | 2022.10.14 |
| [BACS] 정규 세션 1주차 (강원도 소방 데이터) (0) | 2022.09.30 |
| [BACS] 정규 세션 1주차 정리 part2 (0) | 2022.09.26 |
| [BACS] 정규 세션 1주차 정리 part1 (0) | 2022.09.25 |