Warning)아래 코드들은 버전이 바뀌어 정상적으로 작동되지 않을 수도 있습니다. 따로 버전을 명시하지 않았기 때문에 에러가 발생되면 조금씩 수정해 나가면서 사용하시길 바랍니다. 또한, 형편없는 저의 실력으로 코드들이 다소 비효율적일 수 있음을 미리 말씀드립니다. 우연히 이 글을 보게 되신 분들은 참고해주시기 바랍니다.
수집한 데이터를 데이터프레임 형식으로 정리하고 이를 csv파일로 저장하기 위해 pandas를 import하고 pandas 외에 추가적으로 필요한 라이브러리들을 import하겠습니다. 그리고 스크래핑 과정에서 불필요한 창 띄우기를 없애기 위해 웹브라우저에 대한 옵션들을 사전에 지정하겠습니다.
#필요한 라이브러리 import
import time
import pandas as pd
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException, ElementNotInteractableException, NoAlertPresentException, UnexpectedAlertPresentException
from selenium.webdriver.common.by import By
import random
#chrome 웹드라이버 옵션 지정
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
(3) page_review_scrap(): 해당 페이지 스크랩 함수
본격적으로 스크래핑을 진행하는 함수를 정의하도록 하겠습니다. 총 2가지 함수를 정의하게 될텐데 첫 번째는 한 페이지에 대한 스크래핑을 진행하는 정적 스크래핑 함수입니다. page_review_scrap()는 한 페이지 내에 있는 20개의 리뷰를 수집하는 함수입니다. 네이버 쇼핑의 경우 아래 사진과 같이 1번, 2번, 3번 등 각 페이지에 20개씩의 리뷰가 있습니다. 따라서, 모든 리뷰를 계속 가져오기 위해서는 페이지를 넘겨가며 해당 페이지에 있는 리뷰를 긁어와야 합니다. 이를 위해 페이지 내 20개의 리뷰를 가져오는 page_review_scrap() 함수와 페이지를 넘겨가며 사전에 정의한 page_review_scrap()을 적용하는 shopping_review_scraping()함수를 각각 따로 정의해주었습니다.
다시 위 사진을 보게 되면 네이버에서 제공하는 리뷰 데이터에는 평점, 쇼핑몰, 아이디, 날짜, 리뷰 내용, 사진 등의 정보가 담겨 있습니다. 이 중에서 쇼핑몰, 리뷰 내용, 평점 이렇게 3가지 정보만 수집해보도록 하겠습니다. 이후에 진행할 텍스트 분석에서는 리뷰 내용만을 사용하게 되기 때문에 쇼핑몰 정보와 평점 정보는 불필요한 정보이긴 하지만 혹시 모를 상황을 대비해 3가지 정보 모두 수집하였습니다.
쇼핑몰, 리뷰 내용, 평점에 대한 각각의 XPATH를 확인하여 이에 대한 데이터를 각각의 리스트(mall_list, review_list, rating_list)에 넣어주고 이를 데이터프레임 형식으로 정리하여 최종 20개의 리뷰에 대한 스크래핑 결과를 가져오는 방식으로 진행하였습니다.
def page_review_scrap(wd):
try:
alert = wd.switch_to.alert
print(alert.text)
alert.dismiss()
time.sleep(random.uniform(1, 2))
except:
pass
#수집할 데이터를 넣어줄 빈 데이터프레임과 리스트 지정
review_df = pd.DataFrame()
mall_list = []
review_list = []
rating_list = []
#쇼핑몰, 리뷰 내용, 평점에 대한 각각의 XPATH를 통해 데이터를 수집
malls = wd.find_elements(By.XPATH, '//*[@id="section_review"]/ul/li/div[1]/span[2]')
mall_list += [mall.text for mall in malls]
#print(mall_list)
reviews = wd.find_elements(By.XPATH, '//*[@id="section_review"]/ul/li/div[2]/div/p')
review_list += [review.text for review in reviews]
#print(publication_list)
ratings = wd.find_elements(By.XPATH, '//*[@id="section_review"]/ul/li/div[1]/span[1]')
rating_list += [rating.text[-1] for rating in ratings]
#print(review_list)
#20개 리뷰에 대해 수집한 데이터를 데이터프레임 형식으로 변환
new_review_df = pd.DataFrame({'Mall': mall_list,
'Reveiw': review_list,
'Rating' : rating_list})
review_df = pd.concat([review_df, new_review_df], ignore_index = True)
return review_df
(4) shopping_review_scraping: 쇼핑몰 리뷰 스크래핑 함수
앞서 정의한 page_review_scrap() 함수가 단일 페이지에 대한 정적 스크래핑 함수였다면 이제 정의하게 되는 shopping_review_scraping() 함수는 페이지를 이동하며 각 페이지에서 page_review_scrap()함수를 적용하는 동적 스크래핑 함수입니다. 이때, 페이지를 이동하기에 앞서 1점부터 5점까지의 리뷰를 골고루 가져오기 위해 각 평점에 대한 페이지로 먼저 이동하도록 하겠습니다. 만약, 각 평점 페이지로 이동하는 것을 따로 정의하지 않게 되면 5점 리뷰에 대해서만 데이터를 수집하게 되기 때문에 추후에 텍스트를 분석할 때 편향된 결과를 얻게 될 수 있습니다. 따라서, 긍정적인 리뷰, 부정적인 리뷰 모두를 분석할 수 있도록 다양한 평점 리뷰를 가져오는 프로세스를 적용해주어야 합니다.
네이버 쇼핑에서 데이터를 수집할 때 유의해야 할 점 한 가지를 짚고 넘어가겠습니다. 네이버 쇼핑에서는 각 제품에 대한 리뷰를 2000개만 제공하고 있습니다. 따라서, 해당 제품에 대해 리뷰가 2000개 이상이더라도 소비자가 볼 수 있는 리뷰는 2000개로 한정되게 됩니다. 위 사진처럼 전체 리뷰 수가 44,477개이더라도 모든 리뷰를 다 확인할 수는 없다는 것입니다. 스크래핑 과정에서도 이러한 제약이 적용되어 마찬가지로 한 제품 당 2000개의 리뷰만 가져올 수 있게 됩니다. 아마 무분별한 웹크롤링으로 트래픽이 과부화되는 것을 막기 위해서 이러한 제약을 두는 것이 아닐까 생각됩니다. 저도 본격적으로 데이터 수집을 진행하기 전에는 이 부분에 대해 잘 인지하지 못했던 터라 계속 에러가 발생하는 것 때문에 고생하였습니다. 중간 중간 time.sleep()을 랜덤으로 주어가며 수정을 해보기도 했지만 해결이 되지 않다가 결국 수동으로 계속 페이지를 넘어가며 이와 같은 사실을 발견하였습니다. 여튼, 아쉽게도 모든 데이터를 가져오기는 어렵기 때문에 아래 코드에서도 페이지 이동을 100페이지로 제한을 두었습니다. 한 페이지에 20개의 리뷰가 있으니 100페이지면 우리가 가져올 수 있는 2000개 리뷰 제약에 딱 부합하게 됩니다.
def shopping_review_scraping(url, selectable_rate):
wd = webdriver.Chrome('chromedriver', options = chrome_options)
wd.implicitly_wait(3)
# 해당 url로 이동
wd.get(url)
time.sleep(random.uniform(1, 2))
total_review_df = pd.DataFrame()
selectable_rate = [7-i for i in selectable_rate]
for rating in selectable_rate:
rating_xpath = f'//*[@id="section_review"]/div[2]/div[2]/ul/li[{rating}]'
rating_bt = wd.find_element(By.XPATH, rating_xpath)
rating_bt.click()
print('\n****{}점 리뷰페이지로 이동****'.format(7-rating))
time.sleep(random.uniform(1, 2))
page_no = 0
print("[스크래핑 시작]")
while page_no <= 100:
try:
for num in range(1, 12):
next_xpath = f'//*[@id="section_review"]/div[3]/a[{num}]'
review_bt = wd.find_element(By.XPATH, next_xpath)
review_bt.click()
time.sleep(random.uniform(1, 2))
page_no += 1
print('[{}페이지로 이동]'.format(page_no)) #해당 페이지의 리뷰 스크래핑이 완료되면 다음 페이지로 이동
review_df = page_review_scrap(wd)
total_review_df = pd.concat([total_review_df,review_df], ignore_index=True)
while page_no <= 100:
page_no += 1
for num in range(3, 13):
next_xpath = f'//*[@id="section_review"]/div[3]/a[{num}]'
review_bt = wd.find_element(By.XPATH, next_xpath)
review_bt.click()
time.sleep(random.uniform(1, 2))
page_no += 1
print('[{}페이지로 이동]'.format(page_no))
review_df = page_review_scrap(wd)
total_review_df = pd.concat([total_review_df,review_df], ignore_index=True)
except ElementNotInteractableException as ex:
print(ex)
print("[모든 스크래핑이 완료되었습니다.]")
break
except NoSuchElementException as ex:
review_df = page_review_scrap(wd)
total_review_df = pd.concat([total_review_df,review_df], ignore_index=True)
print("[모든 스크래핑이 완료되었습니다.]")
break
return total_review_df
이상으로 STEP2 리뷰 데이터를 수집하기 위한 사전 준비를 마치도록 하겠습니다. 다음 스텝에서는 지금까지 준비한 함수를 활용해서 4개 브랜드의 8개 제품에 대한 스크래핑을 본격적으로 진행하도록 하겠습니다.
Warning) 아래 코드들은 버전이 바뀌어 정상적으로 작동되지 않을 수도 있습니다. 따로 버전을 명시하지 않았기 때문에 에러가 발생되면 조금씩 수정해 나가면서 사용하시길 바랍니다. 또한, 형편없는 저의 실력으로 코드들이 다소 비효율적일 수 있음을 미리 말씀드립니다. 우연히 이 글을 보게 되신 분들은 참고해주시기 바랍니다.
STEP 1. 프로젝트 계획
(1) 분석 목적과 목표
평소에 텍스트 분석에 관심이 많아 유튜브 강의나 책을 통해 조금씩 공부를 하고 있습니다. 대학에서는 경영학을 전공하고 있고 특히 서비스, 마케팅과 관련된 수업을 많이 들었던 터라 지금 공부하고 있는 데이터 사이언스가 서비스 기획이나 마케팅에서 어떻게 활용될 수 있을지 항상 고민을 해왔습니다.
텍스트 마이닝(Text Mining) 또는 텍스트 분석(Text Analysis)이 경영과 접점을 이룰 수 있는 부분은 고객들의 데이터를 활용하는 것이지 않을까 생각합니다. 특히, 고객 데이터 중에서 회사 내부 DB에 저장되는 정형화된 데이터(구매 내역, 사이트 활동 시간 등) 외에 소셜이나 웹사이트에서 얻을 수 있는 비정형 텍스트 데이터에 대한 관심이 날로 커져가는 것 같습니다. 저 또한 고객들이 인터넷 상에 남기는 텍스트 데이터에서 어떻게 하면 인사이트를 발견할 수 있을지 많은 관심을 가지고 있습니다.
따라서, 이번 토이 프로젝트에서는 고객 리뷰 데이터를 가지고 텍스트 분석을 진행하여 상품 기획이나 마케팅 전략 수립에 대한 간단한 제언을 하는 연습을 해보았습니다. 이후 설명 과정에서도 말씀 드리겠지만 분석 결과가 그리 유의미하지는 않으며 상식적인 선에서도 충분히 알 수 있는 결과가 도출되었습니다. 때문에 프로젝트 결과물에 대한 기대는 하기 어렵다고 말씀드릴 수 있습니다. 다만, 빈도 분석과 LDA 토픽 모델링을 적용해보았다는 점, 그리고 한글 텍스트 전처리 과정을 직접 경험해보았다는 점에서 개인적인 의의를 두고 있습니다.
이번에 활용한 텍스트 데이터는 냉동 만두 구매 고객들의 쇼핑몰 리뷰 데이터입니다. 냉동 만두 리뷰를 선택한 것은 별다른 이유는 없고 이 프로젝트를 기획하던 당시 풀무원 만두를 먹고 있었기 때문입니다. 물론 비비고, 풀무원 브랜드의 냉동 만두 사례가 학교 수업 시간에 포지셔닝, 브랜딩 파트에서 많이 활용되는 것을 익히 알고 있기 때문에 이러한 도메인 지식을 활용하면 좋은 분석 결과가 나오지 않을까 하는 기대가 있기도 하였습니다.
결론적으로 이번 토이 프로젝트의 목표은 냉동 만두 구매 고객들의 리뷰 데이터를 분석하여 쇼핑몰에서 만두를 구매하여 소비하는 고객들의 행동과 상황을 확인하는 것입니다. 그리고 이를 활용해 향후 제품 개발과 마케팅 전략에 어떻게 활용할 수 있을지 살펴보는 것입니다.
(2) 데이터 수집 계획
국내에 정말 많은 온라인 쇼핑몰이 있긴 하지만 데이터 수집을 용이하게 하기 위해서는 몇 개의 쇼핑몰로 제한할 필요가 있습니다. 그리고 충분한 sample 수를 얻기 위해 가능한 큰 규모의 온라인몰에서 데이터를 수집하는 것이 좋습니다. 국내 대형 온라인몰 중에는 쿠팡, SSG, 롯데몰 등 대형 유통회사들이 꽤 많지만 저는 네이버쇼핑에서 리뷰 데이터를 수집하였습니다. 한 쇼핑몰의 데이터만 가져오기보다는 여러 쇼핑몰의 데이터를 수집하는 것이 더 객관적인 sampling이 될 수 있을 거라 생각되었기 때문입니다. 하지만, 막상 데이터를 수집한 결과 몇몇 온라인 몰에 집중되어 있어 네이버 쇼핑 데이터를 통해 수집한 의미가 퇴색되긴 하였습니다. 이에 대해서는 추후에 다시 말씀드리도록 하겠습니다.
텍스트 분석을 위해 어느정도의 데이터가 있으면 좋은 지에 대해서는 기준은 없습니다. 많은 데이터가 있으면 그만큼 좋은 결과를 얻을 수 있긴 하지만 수집과 전처리 과정에서 그만큼 많은 시간이 소요됩니다. 사실 제가 많이 고민되었던 부분은 얼만큼의 sample을 수집할지였습니다. 일반적으로 토픽 모델링에 많이 활용되는 뉴스 텍스트는 다양한 토픽들과 다채로운 단어들이 사용되기에 분석 결과의 객관성(?)을 확보하기에 유리합니다. 하지만 리뷰 데이터의 경우 그 길이가 매우 짧고 내용이 한정되어 있어 적은 데이터 sample로는 편향된 결과가 도출되지 않을까 하는 걱정이 되었습니다. 가령, 리뷰 데이터에는 '정말 좋습니다^^', '잘 쓸게요~' 등 단순한 표현들이 많고 리뷰들간 중복되는 것들도 정말 많습니다. 그래서 충분히 많은 데이터를 수집하고자 하는 욕심이 있었습니다. 실제로 리뷰에 대해 토픽 모델링을 시행한 몇몇 사례들을 살펴보니 보통 10만개 이상의 데이터를 수집하는 경우가 많았습니다. 그러나 너무 많은 데이터를 수집하기에는 중간 전처리에 대한 부담이 있어 2만개 데이터를 수집하는 것으로 타협하였습니다.
(3) 분석 방법 선정
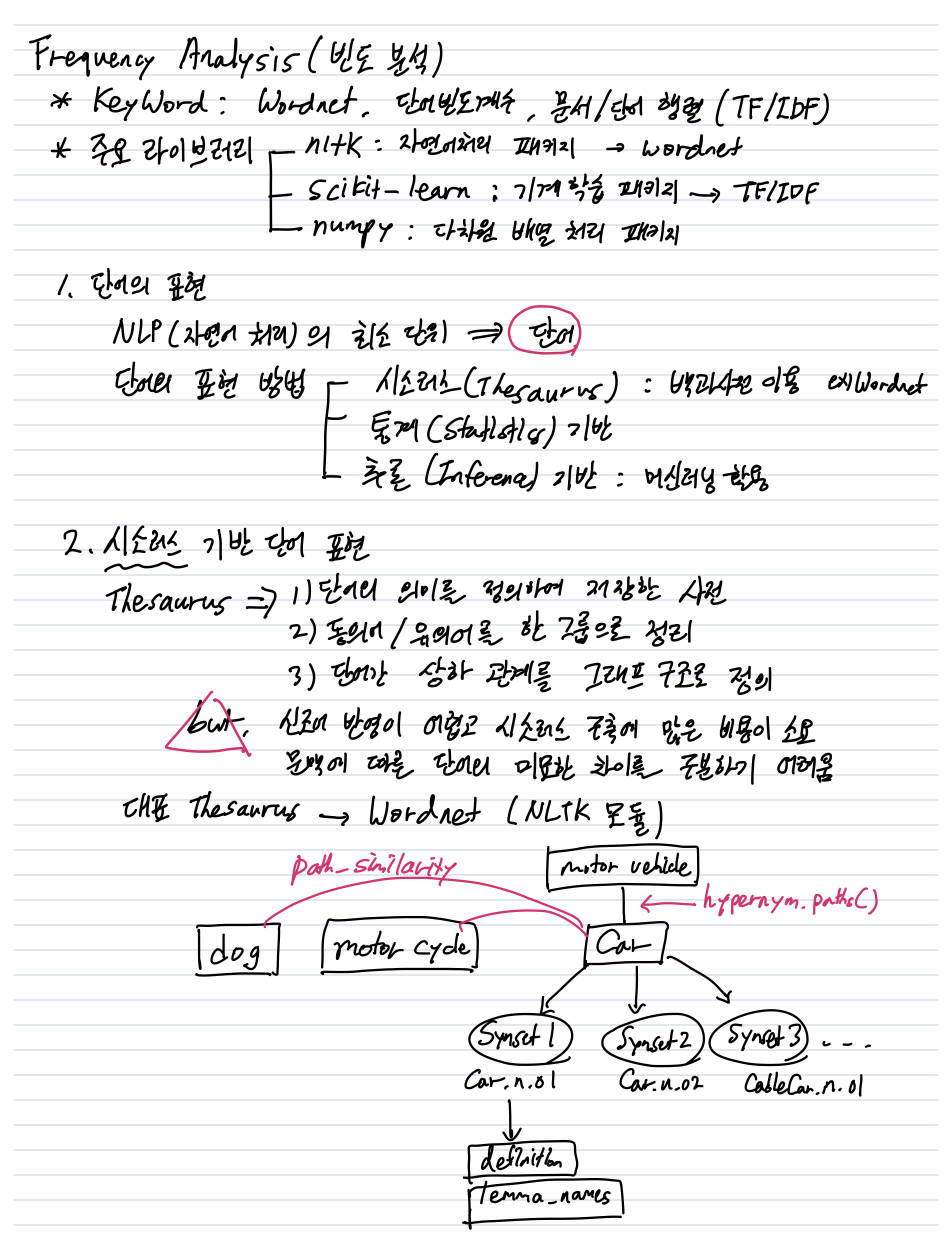
3-1) 빈도 분석을 통한 WordCloud 생성
전처리 과정을 거친 텍스트 데이터에 대해서 단어별 빈도를 확인하고 WordCloud를 생성하도록 하겠습니다. WordCloud를 통해 전체 리뷰 데이터에서 많이 언급된 단어들을 확인하고 냉동 만두 구매 과정에서 생기는 다양한 생각과 경험들을 한눈에 살펴보도록 하겠습니다.
3-2) LDA 토픽 모델링으로 주요 토픽과 핵심 단어 추출
텍스트 데이터에 LDA 토픽 모델링을 적용하여 전체 리뷰 텍스트의 주요 토픽들을 도출하겠습니다. 그리고 각 토픽별 핵심 단어들을 추출하여 앞서 WordCloud를 통해 얻어낸 인사이트를 조금 더 구체화하여 보겠습니다. WordCloud도 마찬가지이지만 토픽 모델링의 경우 분석된 결과에 대해 추가적인 해석의 과정이 필요합니다. 이는 분석하는 사람의 몫이며 도메인 지식과 개인의 분석 역량에 따라 다양하고 주관적인 해석 결과가 나올 수 있습니다. 불행 중 다행인지는 모르겠지만 이번에 도출된 결과물의 경우에는 도메인 지식 없이도 누구나 충분히 해석이 가능한 것으로 보입니다.
Info)아래 포스팅은 LGAimers에서 제공하는 AI 전문가 과정 중 서울대학교 문태섭 교수님의 [Explainable AI(XAI)] 강의에 대한 요약과 생각들을 정리한 것입니다. 정리된 내용들은 강의를 토대로 작성되었으나 수강자인 저의 이해도에 따라 일부 틀린 부분이 있을 수 있다는 점 알려드립니다. 잘못된 점이 발견될 시에는 즉각 수정하도록 하겠습니다. 또한, 강의의 모든 내용을 정리하기는 어렵기 때문에 인상깊었던 내용을 중심으로 정리하였습니다. 따라서, 설명의 맥락이 끊길 수도 있다는 점 양해 부탁드립니다.
0. Introduction
이번 3강에서는 XAI 모델의 성능을 평가할 수 있는 여러 metric들과 XAI의 신뢰성에 대한 연구들을 살펴보았습니다. 지도, 비지도 학습에서 model이 얼마나 정확한지를 확인하기 위해 model의 성능을 측정하는 것이 필수적인 과정이라 할 수 있는데 마찬가지로 XAI 모델 또한 그 성능을 점검하는 것이 반드시 필요하며 이를 위한 다양한 측정 지표와 방법들이 존재합니다. 다만, XAI의 경우 예측 결과의 정확도나 오차보다는 그 예측 결과를 출력하는 과정에 초점이 맞춰져 있기 때문에 다소 다른 측정 방식이 사용됩니다.
1. Human-based Visual Assessment
첫 번째로 가장 단순하며 원시적인 방법이라 할 수 있는 human-based visul assessment가 있습니다. 인간이 직접 개입하여 성능을 측정하는 방식이라고 할 수 있습니다. Amazon Mechanical Turk라고 불리는 AMT test에서는 사람이 직접 model이 내놓은 설명을 보고 이를 평가하는 test를 진행하게 됩니다. 가령, 사람들에게 모델이 출력한 결과에 대한 설명을 보여주고 문제(ex. 설명을 보고 무엇이 보이는지 선택)를 풀게 합니다. 그리고 문제에 대해 사람이 선택한 정답과 model의 분류 결과를 비교하여 모델의 설명이 잘 되었는지 확인하게 됩니다. 만약, 사람과 model 사이의 오차가 너무 크다면 그것은 결국 model이 설명을 잘 해내지 못했다는 것을 의미하며 모델의 성능을 높일 필요가 있음을 나타냅니다. 이러한 방식은 인간의 노동력을 필요하는 작업이기 때문에 비용이 많이 들게 됩니다.
출처: 문태섭 교수님 강의자료
2. Human Annotation
두 번째는 human-annotation을 이용하는 방식으로 인간이 이미지에 달아놓은 localization, semantic segmentation 정보를 ground truth로 활용해 모델의 설명을 평가하는 방법입니다. 대표적으로 'pointing game' 과 'weakly supervised semantic segmentation' 방식이 있습니다. 'pointing game'은 bounding box를 활용하는 방법으로 인간이 그려낸(?) bounding box 안에 모델의 설명이 포함되는 지를 측정하는 것입니다. 모델이 설명을 만들어 낼 때 가장 중요하게 생각하는 pixel이 있을 것인데 그 pixel이 인간의 bounding box 범위 안에 있다면 어느 정도 잘 설명을 하는 것이라고 평가할 수 있습니다.
'weakly supervised semantic segmentation'은 pixel마다 label이 주어져 있는 semantic segmentation 정보(이를 ground-truth로 설정)를 이용해 모델이 하이라이트한 설명과 비교해 정확도를 측정하는 방법입니다. 이때, metric으로 IoU(Intersection over Union)를 사용하게 되는데 이는 단어 뜻 그대로 합집합 대비 교집합의 비율로서 많이 겹쳐 수치가 높을 수록 좋은 모델이라는 것을 보여주게 됩니다. 아래 그림과 같이 두 semantic segmentation 사이에 intersection 부분이 많을 수록 model이 잘 설명을 짚어냈다고 할 수 있습니다.
출처: 문태섭 교수님 강의자료
'pointing game', 'weakly supervised semantic segment'와 같은 방법들은 human annotation data를 구해야 하기 때문에 상당한 시간과 노력이 또 필요하게 됩니다. 그리고 어렵게 data를 구했다고 하더라도 localization과 segmentation label 정보가 절대적인 기준이 될 수 있는지 그 타당성 또한 불분명하여 적용하기가 어려운 경우도 있습니다.
3. Pixel Perturbation
세번째로 pixel에 교란을 주어 출력값에 어떤 변화가 있는지 확인 비교하는 방식이 있습니다. 이미지의 특정 부분을 가리게 되었을 때 해당 class로 분류하게 되는 score 점수에 큰 변화가 생긴다면 그 가려진 부분은 모델의 prediction에 가장 핵심적인 역할을 한 부분이라고 판단할 수 있습니다. 한번 아래의 그림을 살펴보겠습니다. castle에 해당하는 부분을 지운 가운데 이미지에 대해서 모델이 castle이라고 분류할 score가 다른 부분을 지운 이미지보다 훨씬 더 크게 떨어지는 것을 확인할 수 있습니다. 어느 부분을 가리느냐에 따라 score값이 변하는 정도는 달라질 것입니다. 위의 경우에는 castle부분을 지운 사진에 대해서 score가 많이 떨어지게 되었고 이는 그만큼 모델이 이 이미지에서 castle에 해당하는 부분을 잘 찾아내고 있다는 것을 의미하게 됩니다. pixel perturbation에서는 'AOPC(Area Over the MoRF Perturbation Curve)', 'Insertion', 'Deletion'과 같은 각종 metric을 사용해 정확하게 비교 측정할 수 있습니다.
Info)아래 포스팅은 LGAimers에서 제공하는 AI 전문가 과정 중 서울대학교 문태섭 교수님의 [Explainable AI(XAI)] 강의에 대한 요약과 생각들을 정리한 것입니다. 정리된 내용들은 강의를 토대로 작성되었으나 수강자인 저의 이해도에 따라 일부 틀린 부분이 있을 수 있다는 점 알려드립니다. 잘못된 점이 발견될 시에는 즉각 수정하도록 하겠습니다. 또한, 강의의 모든 내용을 정리하기는 어렵기 때문에 인상깊었던 내용을 중심으로 정리하였습니다. 따라서, 설명의 맥락이 끊길 수도 있다는 점 양해 부탁드립니다.
0. Introduction
이번 2강에서는 지난 시간의 saliency map-based 기법에 대해 더 알아보고 perturbation-based 방식에 대해 새로 학습하였습니다. perturbation-based model들은 기본적으로 data에 noise를 주거나 변형을 주어 algorithm의 예측 확률이 떨어지는 정도를 비교하는 공통된 아이디어를 가지고 있습니다. 저는 이 점이 굉장히 흥미로웠고 놀라웠습니다. data에서 가장 중요한 포인트가 없어지거나 왜곡이 되면 예측 결과에 큰 변화가 생긴다는 점을 역으로 활용하여 설명을 해낸다는 것이 정말 천재적인 발상의 전환이 아닐 수 없습니다. 이전의 지도학습에서 kernel trick을 통해 2차원의 data를 3차원으로 mapping하여 linear seperable하게 만들 수 있다는 것을 배운적이 있는데 이 못지않게 간단하지만 훌륭한 아이디어라고 생각됩니다.
1. Saliency map-based
1.1 Class Activation Map (CAM)
CAM에서의 핵심은 GAP(Global Average Pooling)이라는 layer을 만들어 이를 통해 설명을 제공한다는 점입니다. global average pooling은 cnn layer에서 출력된 각 activation map들의 평균 activation을 연산하게 됩니다. 그리고 평균 activation을 soft max layer을 통해 선형 결합하여 각 label에 대한 확률로 계산하게 됩니다. 각 activation map의 평균 activation과 이에 선형 결합되는 w가 크다는 것은 최종 class 분류에 큰 영향을 주기 때문에 설명력이 있는 부분이라는 것을 의미하게 됩니다.
출처: 문태섭 교수님 강의 자료
CNN의 최종 layer의 해상도는 다소 떨어지기 때문에 upsampling을 통해 최종 시각화를 진행하게 됩니다. 아래 식은 class C에 대한 cam 결과를 나타낸 것입니다. summation 안의 A값은 activation map에 대한 값을 말하며 w값은 선형 이에 선형 결합되는 가중치값입니다. 위의 gap layer을 표현한 식이라고 생각하면 됩니다.
출처: 문태섭 교수님 강의자료
cam은 이미지의 class에 해당하는 부분을 잘 하이라이트하며 적절한 threshold를 통해 bounding box까지 얻을 수 있다고 합니다. 이러한 성능적인 우수성 덕분에 objection detection, semantic segmentation과 같은 응용 분야에 활용이 되며 이를 weakly supervised learning이라고 합니다. 하지만 cam 방식은 gap layer가 있는 모델들에만 적용이 가능하여 model-specific하다는 단점이 있으며 마지막 convolutional layer에서의 activation map에서만 값을 얻을 수 있기에 visualization의 해상도가 다소 떨어집니다.
1.2 Grad-CAM
Grad-CAM은 CAM의 단점을 극복하여 gap이 없어도 적용이 가능한 방법입니다. 아래식을 비교해보면 grad-cam의 경우 cam과 달리 weight 값을 마지막 convolutional layer에서의 값을 사용하지 않습니다.
해당activation들에서 구한gradinet를global average pooling과정을 거쳐W값으로 사용한다. 즉, 어떤W가 특정모델구조를 가지고 학습된W를 사용하는 것이 아니라, 어느activation map의gradient를 구한 후, 그것의global average pooling값으로W를 적용하는 것이다.
활용하고자 하는layer의activation map까지backpropagation을 진행하여gradinet를 구하고,gradient를pooling해서 해당activation map을 결합하는W로 사용하여 최종 설명을 구한다.
출처: 문태섭 교수님 강의자료
grad-cam은 모델이 어떤 출력 구조를 가지고 있더라도 그에 관계없이 backpropagation을 통해 gradient를 구할 수만 있다면 다 적용이 가능하다는 장점이 있습니다. 하지만, 평균 gradient를 사용하는 것이 종종 정확성에 있어 아쉬움이 있을 때가 있습니다. gradient가 크다는 것은 해당 activation에 대한 출력 값의 민감도가 크다는 것을 의미하지만 최종 결과를 출력하는 데에 있어 중요도를 정확히 반영하지 않는다는 것입니다.
2. Perturbation-based
앞서 살펴본 saliency map-based 방식은 white-box 방식입니다. 하지만 모델의 정확한 구조나 계수를 모르는 상태에서 입출력에 대한 정보만 가지고 있는 상태에서는 perturbation-based 방식이 사용 가능합니다. 입력 데이터를 조금씩 바꾸면서 그에 대한 출력을 보고 그 변화에 기반해서 설명하는 방식입니다.
lime은 매우 복잡한 비선형적인 특징을 보이는 classifier들이 local하게는 선형적인 모델로 근사화가 가능하다는 아이디어에서 착안되었습니다. 주어진 데이터를 조금씩 교란(perturbate)해가며 이를 모델에 여러번 통과시키며 나오는 출력을 보고 입출력 pair를 간단한 선형 모델로 근사하여 설명을 얻어내는 방법입니다. model-agnostic하고 black-box한 설명이라는 특징을 가지고 있습니다. 가령, 이미지를 여러 super-pixel들로 나눈 다음 분리된 super-pixel들 중 random하게 선택하여 이미지를 교란시킵니다. 그리고 perturbed된 이미지를 모델을 통해 예측하고 예측된 결과에 대한 확률을 비교합니다. 아래 그림과 같이 각 perturbed된 이미지에 대한 확률들이 다르게 나타나는데 이미지와 확률의 pair을 통해 선형계수를 학습합니다. 선형계수들을 통해 개구리 class로 예측할 때 중요한 역할을 한 super pixel들을 최종적으로 설명해낼 수 있게 됩니다.
출처: 문태섭 교수님 강의자료
lime 방법은 black-box설명 방법으로서 딥러닝 모델 뿐 아니라 주어진 입력과 그에 대한 출력만 얻을 수 있으면 어떤 모델에 대해서도 다 적용할 수 있는 설명 방법입니다. 하지만, 계산 복잡도가 높고 local하게도 non-linear한 경우에는 모델이 잘 적용되지 않는 단점이 있습니다.
2.2 RISE(Randomized Input Sampling for Explanation)
rise는 lime과 마찬가지로 교란을 통해 설명을 진행하는 방식입니다. 아래 그림과 같이 랜덤한 mask를 씌운 input 이미지들을 모델에 입력하여 얼마나 확률이 떨어지는지 비교하여 하이라이트하게 됩니다.
출처: 문태섭 교수님 강의자료
rise 방식은 lime에 비해 더 좋은 성능을 보이지만 여러개의 mask를 만들어야 하기 때문에 계산 복잡도가 증가하고 mask들을 몇번 만드느냐에 따라 다른 결과들(noise)이 나올 수 있다는 단점이 있습니다.
3. Influence function-based
black-box model에 대한 설명을 도출하는 방법 중 하나로 influence function-based 방식이 있습니다. 각 test image를 분류하는데 가장 큰 영향을 미친 train image가 해당 분류에 대한 설명이라고 보는 아이디어에서 시작된 XAI 방법입니다. 말로서는 조금 어려울 수 도 있으니 아래 그림을 통해 이해해보도록 하겠습니다.
하나의 예시로 RBF 커널을 사용한 SVM model과 cnn기반의 Inception model을 가지고 니모 물고기(test image)를 분류하는 작업을 진행했다고 가정해보겠습니다. 이 두 모델이 test image를 분류하는 데 사용한 기준은 서로 상이합니다. RBF SVM model의 경우 단지 색깔이 비슷한 이미지들을 가지고 test image에 대한 예측을 진행하였습니다. 니모 물고기와는 전혀 다른 종의 물고기이지만 색깔은 같은 엉뚱한 이미지를 기준으로 분류를 한 것입니다. 반면, Inception 모델의 경우 test image와 같은 종인 니모 물고기를 기준으로 분류 결과를 예측해냈습니다. 이처럼 분류 작업에 큰 영향을 미친 data를 통해 모델의 예측을 설명해낼 수 있고 그것이 합리적인지를 확인하여 model이 잘 학습되었는지 판단할 수 있습니다.
Info)아래 포스팅은 LGAimers에서 제공하는 AI 전문가 과정 중 서울대학교 문태섭 교수님의 [Explainable AI(XAI)] 강의에 대한 요약과 생각들을 정리한 것입니다. 정리된 내용들은 강의를 토대로 작성되었으나 수강자인 저의 이해도에 따라 일부 틀린 부분이 있을 수 있다는 점 알려드립니다. 잘못된 점이 발견될 시에는 즉각 수정하도록 하겠습니다. 또한, 강의의 모든 내용을 정리하기는 어렵기 때문에 인상깊었던 내용을 중심으로 정리하였습니다. 따라서, 설명의 맥락이 끊길 수도 있다는 점 양해 부탁드립니다.
0. Introduction
이번
1. Limitation of Supervised Learning
딥러닝을 기반으로 한 지도 학습은 이미지 처리, 음성 처리, 자연어 처리 등 다양한 분야에서 비약적인 기술 혁신을 이루어냈습니다. 그리고 많은 어플리케이션 분야에 활용되며 실질적으로 인간의 삶에도 영향을 미치기 시작했습니다. 하지만 우수한 성능에도 불구하고 지도학습 기반인 딥러닝 모델에는 중요한 한계점이 있습니다. 바로 대용량 학습 데이터로부터 학습하는 모델 구조가 점점 복잡해지면서 그 내부를 이해하기 어렵게 되었다는 것입니다. 즉, 모델에 입력을 넣으면 출력을 얻을 수 있는 black-box 방식으로 구현된다는 것만 확인될 뿐입니다. 그리고 이러한 점 때문에 여러 문제가 발생하게 됩니다. 모델이 예측한 결과가 인간에게 직접적인 영향을 미치는 경우 그 예측 결과가 타당한지에 대한 설명과 검토를 진행할 수 없다면 실효성에 있어 제약이 생기게 됩니다. 이와 관련된 흥미로운 사례 중 하나는 AI가 흑인과 동양인에 대해 인종 편향적인 예측 결과를 내놓았다는 것이 있습니다. 또한, 미국 재소자에 대한 재범죄율 예측 시스템인 Compass의 예측 결과를 설명한 결과 인종에 따라 다른 예측 결과를 보인 것이 확인되었습니다. 이처럼 제아무리 뛰어난 성능을 보이는 인공지능 모델이라고 하더라도 모델이 내놓은 결과가 생각보다 이상한 설명을 가지는 경우가 있습니다. 바로 이러한 점 때문에 설명가능한 인공지능(XAI)에 대한 연구와 개발이 필요하다고 할 수 있습니다.
2. Explainability / Interpretability
설명 가능한 인공지능(XAI)에서 '설명 가능하다'는 것이 무엇을 의미하는지 살펴보면 다양한 해석이 가능합니다. 사전적으로 interpretability은 사람이 그 이유를 이해할 수 있게 해주는 것, 설명을 통해 모델이 결과를 예측할 수 있게 해주는 것, 이유를 설명할 수 있게 해주는 것 등 다양한 해석이 있을 뿐 구체적인 방법에 대해서는 알 수 없습니다. 다만, 최근의 연구들을 살펴보면 시각화를 통해 모델의 예측 결과에 영향을 미친 특징들을 찾아내어 설명을 하는 방식이 하나의 방법론으로서 활용되고 있음을 알 수 있습니다.
3. Taxonomy of XAI Methods
XAI의 방법론을 다양한 기준에 의해 분류 해보면 다음과 같습니다. 가령, 일반적으로 많이 활용되는 선형 모델은 선형 계수(가중치)가 설명에 직접적인 영향을 주는 요소이기 때문에 Intrinsic하며, 전체 데이터에 대한 학습 결과를 설명하기 때문에 Global하고 모델의 정확한 구조가 선형회귀식으로 명확하기 때문에 White-box하고 선형 구조에만 적용 가능하기 때문에 Model-specific한 설명 방법입니다.
Local 주어진 특정 데이터에 대한 예측 결과를 개별적으로 설명하려는 방법
설명 범위
Global 전체 데이터셋에서 모델의 전반적인 행동을 설명하고자 하는 방법
White-box 모델의 내부 구조를 정확하게 알고 있는 상황에서 설명을 시도하는 방법
모델의 구조 확인 가능여부
Black-box 모델의 내부 구조는 모르는 상태에서 단순히 모델의 입출력만 가지고 설명을 시도하는 방법
Intrinsic 모델의 복잡도를 훈련하기 이전부터 설명하기 용이하도록 제한한 뒤 학습을 시켜서 그 후 학습된 모델을 설명하는 방법
모델 통제 여부
Post-hoc 임의의 모델 훈련이 끝난 뒤에 XAI 방법을 적용하여 모델의 행동을 설명하는 방법
Model-specific 특정 모델 구조에만 적용 가능
적용 가능 범위
Model-agnostic 모델의 구조와 관계없이 어느 모델에도 항상 적용 가능
4. Saliency map-based
4.1 Simple Gradient Method
Saliency map-based 방식은 예측 결과에 대한 설명을 히트맵 방식으로 이미지에서 중요하게 작용하는 부분을 하이라이트하는 방식입니다. 다양한 method들이 존재하는데 그 중 simple gradient method는 입력에 대한 모델의 gradient로 설명을 제공하게 됩니다. f(x)함수에 입력된 x0에 대한 출력에 대해 입력값의 각 pixel의 gradient를 계산해서 그 값을 각 pixel의 중요도로 사용합니다. 이러한 gradient 계산을 통해 pixel이 변화할 때 출력이 얼마나 변하는 지를 알 수 있기 때문에 각 pixel의 중요도를 파악할 수 있습니다.
아래 그림을 보면 모델이 강아지와 과일을 출력하는데 설명하는 부분을 하이라이트한 것을 볼 수 있습니다. 아주 분명하게 표시하지는 않았지만 어느정도 영역에 맞추어 표시했음을 알 수 있습니다. 저는 아직 이미지 처리를 공부해보지 않아 이 부분이 너무나도 신기하고 놀라웠습니다. 요즘 자율주행자동차가 각광을 받으며 image detection에 대한 연구가 활발히 진행되고 있는데 한번 관심을 가져보면 좋을 것 같다는 생각이 들었습니다.
simple gradient method는 back-propagation을 통해 간편하게 계산할 수 있다는 장점이 있지만 매우 noisy한 결과를 가져올 수도 있다는 단점이 있습니다. 똑같은 예측 결과를 가지고 있는 조금씩 변하는 이미지들에 대한 설명이 다르게 나타나게 되며 이는 작은 noise에 대한 입력 gradient 값이 매우 noisy하다는 것을 나타냅니다.
출처: 문태섭 교수님 강의자료
4.2 SmoothGrad
위의 문제를 보완하기 위해 SmoothGrad를 사용할 수 있습니다. SmoothGrad는 입력 데이터에 가우시안 noise를 섞어주어 noise가 섞인 input의 gradient들을 평균내어 설명하는 방식입니다. 이렇게 하면 noisy한 gradient들은 제거가 되고 평균적인 gradient값이 남게 된다고 합니다. 평균적으로 noise gradient를 계산하는 횟수는 50회 정도입니다. 아래 그림을 보면 기존의 simple gradient를 사용한 saliency map에 비해 smoothgrad 방식이 더 중요한 pixel을 찾아내는 것을 확인할 수 있습니다. smoothgrad는 평균을 통해 더 명확한 설명이 가능하게 된다는 장점이 있고 대부분의 saliency map에 사용할 수 있습니다. 하지만 noise의 횟수만큼 더 많은 computational load가 발생하는 단점이 있습니다.