info) 정규세션 2주차 Titanic 시각화 실습
Titanic 데이터를 활용하여 시각화 그래프 그리기
1. 라이브러리 import 및 환경 설정
#주피터 노트북 환경 설정
from IPython.core.display import display, HTML
display(HTML("<style>.container {width:80% !important;}</style>")) #주피터 노트북 셀 확장
%matplotlib inline #그래프를 셀에서 그리기
#필요한 라이브러리 import
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from scipy import stats
import warnings
warnings.filterwarnings('ignore')
#맷플로립 그래프 초기 환경 설정
mpl.rcParams['figure.figsize'] = (12,8) #figure size default 설정
mpl.rcParams['font.family'] = 'NanumGothic' #한글 폰트 default 설정
mpl.rcParams['font.size'] = 15 #폰트 사이즈 default 설정
plt.rcParams['axes.unicode_minus'] = False #한글 마이너스 기호 깨짐 방지
%config InlineBackend.figure_format='retina' # 그래프 글씨를 뚜렷하게 설정2. Titanic 데이터 불러오기
df = pd.read_csv('./Titanic.csv')
df.head(3)3. 시각화 작업
Graph1) 생존자 연령 분포에 대한 Violin Plot(바이올린 플롯)
1-1. 시각화 목적
1) 타이타닉 생존자에 대한 대략적인 분포를 파악하기 위한 목적에서 그래프를 그려보았습니다.
2) 구체적으로 생존에 영향을 끼친 2개의 feature값 'Sex(성별)'과 'Pclass(객실등급)' 각각에 대한 생존/사망자들의 연령 분포를 확인하고자 그래프를 그렸습니다.
1-2. 시각화 과정 소개
1) 분포를 확인할 수 있는 방법으로 hist plot, box plot 등 여러 방법이 있지만 hist plot은 두 히스토그램이 겹치게 그려진다는 단점이 있고 box plot은 그래프에 대한 지식이 없이는 직관적으로 해석하기 어렵다는 단점이 있습니다. 따라서, 이 둘을 보완할 수 있는 Violin plot을 선택하였습니다.
1-3. 그래프 그리기
#subplot으로 2개의 그래프를 한번에 그릴 수 있도록 설정
fig,ax=plt.subplots(1, 2, figsize=(18,8))
#첫 번째 그래프
sns.violinplot(data=df, x="Pclass", y="Age", hue="Survived", split = True, ax = ax[0])
ax[0].set_title('Pclass별 Survived의 Age 분포', fontsize = 20, fontweight ='bold')
ax[0].set_yticks(range(0,100,10)) #연령의 bin을 10으로 설정
#두 번째 그래프
sns.violinplot(data=df, x="Sex", y="Age", hue="Survived", split = True, ax = ax[1])
ax[1].set_title('Sex별 Survived의 Age 분포', fontsize = 20, fontweight ='bold')
ax[1].set_yticks(range(0,100,10)) #연령의 bin을 10으로 설정
plt.tight_layout()
plt.show()
1-4. 자체 피드백
1) 위 그래프를 통해서는 생존에 대한 심층적인 분석이 불가능하다고 보입니다. 우리의 목적은 생존에 어떤 요인들이 영향을 미쳤고 어떤 사람들이 생존에 유리했는지 파악하는 것인데 상기의 그래프를 통해서는 이를 분석하기 어렵다고 생각됩니다.
2) 가령, 연령별 생존 여부를 확인하기 위해서는 생존자 분포가 아닌 생존율을 살펴볼 필요가 있습니다. 각 연령별로 인원수가 같지 않기 때문에 절대적인 수를 가지고 비교하게 되면 잘못된 해석이 될 수 있습니다.
3) 때문에 단순 count를 기반으로 하는 그래프가 아닌 생존율을 비교하는 그래프로 다시 바꾸도록 하겠습니다. 아래 그래프들은 상단의 그래프 각각을 분석 목적에 맞춰 새로 변환한 것입니다.
1-5. 피드백을 반영한 그래프
1) 연령대별 생존율
def ageband(x):
if x < 10:
return '0-9세'
elif x < 20:
return '10대'
elif x < 30:
return '20대'
elif x < 40:
return '30대'
elif x < 50:
return '40대'
elif x < 60:
return '50대'
elif x < 70:
return '60대'
elif x < 80:
return '70대'
else:
return '80대 이상'#ageband()함수를 통해 연령대를 나타내는 새로운 컬럼 Ageband 생성
df['Ageband'] = df['Age'].apply(lambda x: ageband(x))
df.sort_values('Ageband', inplace = True)
#연령대별 생존율에 대한 barplot
sns.catplot(data=df, x="Ageband", y="Survived", kind="bar", height=4, aspect=3)
#생존율 평균값을 그리기
mean_survived = np.round(df['Survived'].mean(), 3) #전체 승객에 대한 생존율 평균
plt.axhline(mean_survived, label='평균', linestyle = '--', linewidth = 3, color = 'r') #평균값을 y좌표로 하는 수평선 생성
plt.text(7, mean_survived + 0.05, f'평균값 : {mean_survived}', fontsize=15, fontweight = 'semibold') #평균에 대한 텍스트 출력
plt.xlabel('연령대')
plt.ylabel('생존율')
plt.ylim((0, 1))
plt.title('연령별 생존율')
plt.show()
분석 : 10대 이하, 80대 이상을 제외하고 대부분의 연령대는 평균 생존율에 근사해 있습니다. 70대의 경우에는 생존자가 없으며, 10대 이하의 생존율은 평균 이상이고 80대 이상의 생존율은 평균 이하입니다. 어린이에 비해서 노인들이 생존에 있어 취약한 면이 있었다고 보입니다.
2) 객실 등급별 남여 생존율 차이
#Pclass와 Sex별 생존율을 나타내는 df
pd.DataFrame(df.groupby(['Pclass', 'Sex'])['Survived'].mean())fig = sns.catplot(data=df, x="Sex", y="Survived", col="Pclass", kind="bar", height=4, aspect=.6,)
fig.set_axis_labels("", "생존율")
fig.set_xticklabels(["남성", "여성"])
fig.set_titles("{col_var} {col_name}")
fig.set(ylim=(0, 1))
plt.show()
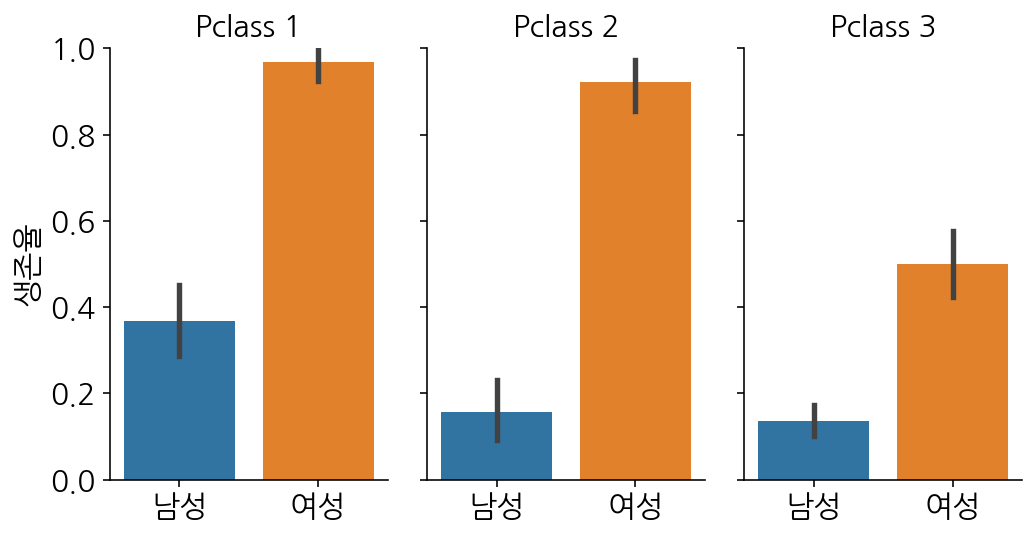
분석 : 전반적으로 남성보다 여성의 생존율이 월등히 높습니다. 남성의 경우에는 1등급 객실의 생존율이 다른 객실보다 높은 편이며 남녀 상관없이 3등급 객실의 생존율이 가장 낮습니다. 특히, 여성에 있어 다른 1,2등급 객실은 생존율이 90% 이상으로 높은 편이지만 3등급 여성 승객들은 50%의 매우 낮은 확률을 보이고 있습니다. 이 점에 대해서 그래프 상으로만은 이유를 발견하기 어렵지만 다른 참고 자료를 통해서 그 원인에 대해 찾아볼 수 있을 것 같습니다.
'BACS > 정규세션' 카테고리의 다른 글
| [BACS] 정규 세션 2주차 Tourism 시각화 (1) (0) | 2022.11.18 |
|---|---|
| [BACS] 정규 세션 2주차 Titanic 시각화 (2) (0) | 2022.11.04 |
| [BACS] 정규 세션 1주차 (강원도 소방 데이터) (0) | 2022.09.30 |
| [BACS] 정규 세션 1주차 (Pandas 실습 - World2012) (0) | 2022.09.27 |
| [BACS] 정규 세션 1주차 정리 part2 (0) | 2022.09.26 |