info) BACS 1주차는 Titanic 데이터를 사용하여 Pandas 실습을 진행하였습니다.
실습을 위한 Titanic csv 파일은 Kaggle의 'Titanic - Machine Learning from Disaster' 페이지에서 다운로드 가능하며 원본 파일은 train.csv이나 다른 파일과의 혼동을 방지하기 위해 Titanic으로 파일명을 변경하여 진행하였습니다.
4. 파생변수 만들기
'Age' 컬럼을 변형하여 연령대를 의미하는 'AgeBand' 컬럼을 새로운 파생변수로 추가하고자 합니다. 이를 위해서 2가지 방법을 사용할 수 있는데 각각의 방법을 살펴보겠습니다. 'AgeBand' 컬럼의 value는 '20대 미만', '20대', '30대', '40대', '50대', '60대 이상' 총 6개의 값으로 이루어지도록 구성하겠습니다. 연령대를 더 세분화하고 싶다면 조건을 더 추가해 주시면 됩니다.
1) loc 메소드 사용
먼저 'AgeBand'라는 컬럼을 빈 값들로 채워 지정해줍니다. 그리고 loc[행에 대한 부분, 열에 대한 부분]을 사용해 행부분에 'Age'값에 대한 조건을 지정해주고 열부분에는 'AgeBand'를 넣어 조건에 맞는 해당되는 부분을 빈값에서 연령대로 바꿔주면 됩니다.
df['AgeBand'] = '' #빈값으로 구성된 새로운 AgeBand 컬럼을 생성
#loc메소드에 각 조건을 지정하여 빈값을 해당 연령대로 변경
df.loc[(df['Age'] < 20), 'AgeBand'] = '20대 미만'
df.loc[(df['Age'] >= 20) & (df['Age'] < 30), 'AgeBand'] = '20대'
df.loc[(df['Age'] >= 30) & (df['Age'] < 40), 'AgeBand'] = '30대'
df.loc[(df['Age'] >= 40) & (df['Age'] < 50), 'AgeBand'] = '40대'
df.loc[(df['Age'] >= 50) & (df['Age'] < 60), 'AgeBand'] = '50대'
df.loc[df['Age'] >= 60, 'AgeBand'] = '60대 이상'2) age_band() 함수를 정의하고 apply lambda 적용
다른 방법으로는 if문을 통해 각 연령대를 반환하는 함수를 정의하고 이를 컬럼에 apply lambda를 통해 적용하는 것입니다. 아래 코드를 통해 직접 살펴보겠습니다.
#age_band() 함수 정의
def age_band(x):
if x < 20:
return '20대 미만'
elif x < 30:
return '20대'
elif x < 40:
return '30대'
elif x < 50:
return '40대'
elif x < 60:
return '50대'
else:
return '60대 이상'#apply lambda를 통해 함수를 적용하여 'AgeBand'컬럼 생성
df['AgeBand'] = df['Age'].apply(lambda x: age_band(x))5. 그룹별로 집계하기
groupby를 통해 생존률에 대해 여러 조건으로 집계를 해보도록 하겠습니다. Sex별, Pclass별, Embarked별, AgeBand별 등 각 그룹별 생존율을 살펴보고 이를 통해 타이타닉 침몰 사건에서 생존을 한 사람들의 특징들을 확인해보시기 바랍니다. 번쩍이는 인사이트는 아니지만 이러한 방식으로 가설들을 세울 수 있다는 점을 살펴 볼 수 있습니다.
추가) 생존률은 mean() 평균을 통해 구할 수 있습니다. 'Survived'컬럼이 생존 시 1, 사망 시 0으로 되어 있기 때문에 이들 값들의 평균은 '생존인원 / 전체 인원'과 동일하며 이는 생존율이라고 할 수 있습니다.
#Sex별 생존율
df.groupby(['Sex'], as_index=False)['Survived'].mean()
#Pclass별 생존율
df.groupby(['Pclass'], as_index=False)['Survived'].mean()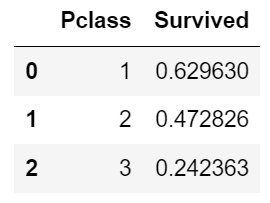
#Embarked별 생존율
df.groupby(['Embarked'], as_index=False)['Survived'].mean()
#'AgeBand'별 생존율
df.groupby(['AgeBand'], as_index=False)['Survived'].mean()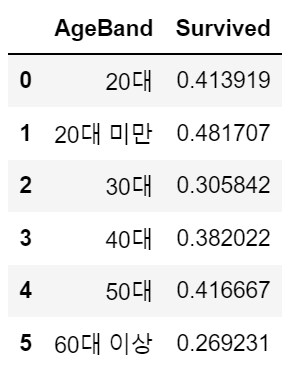
[분석결과]
1) Sex별 생존율에서 남성에 비해 여성의 생존율이 월등히 높았습니다. 탈출 과정에서 여성, 노인 등과 같이 보호 대상들을 우선으로 하였기 때문이지 않을까 짐작됩니다. AgeBand별 생존율에서는 60대 이상을 제외하고는 거의 비슷한 확률 분포를 보였습니다. 노인분들의 경우 아무리 탈출 우선 순위에 두었다 하더라도 신체적인 제약으로 인해 생존율이 현저히 떨어진 것이 아닐까 생각됩니다.
2) Pclass별 생존율에서는 1등급에서 낮은 등급으로 갈수록 생존율이 급격히 떨어지는 것을 확인할 수 있었습니다. 1등급 탑승객들을 우선으로 하여 탈출을 진행했을 수도 있고 1등급 객실이 2,3등급에 비해 위치 상 탈출 경로에 더 가까웠을 수도 있습니다. 물이 먼저 차오르는 낮은 층에 낮은 등급의 객실이 많이 분포되어 있었을 것 같다는 생각이 듭니다. 이러한 분석 결과는 타이타닉호의 선실 구조 자료를 통해 검증해볼 필요가 있을 것입니다.
3) 가장 흥미로웠던 것은 Embarked별 생존율이었습니다. 개인적으로 탑승 지역은 생존율과 큰 관계가 없을 것으로 생각하였습니다. 따라서, Embarked별 생존율은 비슷하게 분포되었을 것이라고 예상하였습니다. 하지만 다른 지역과 달리 C지역에서 탑승한 승객의 생존확률이 50%이상이라는 수치를 보였습니다.
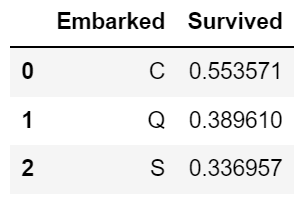
이것이 유의미한 수치인지에 대해 추가적인 가설검증의 과정이 필요하지만 대충 짐작해보면 C지역의 탑승객 중 부유층이 많지 않았을까 생각됩니다. 부유층일수록 1등급칸에 많이 탑승했을 것이고 고로 탈출 확률이 높았을 것입니다. 이를 위해 한번 Embarked별 평균 Fare(혹시 몰라 중앙값도 확인)와 Pclass 분포를 확인해보겠습니다. 즉, 탑승지역에 따라 부유층의 비율이 다른지 살펴보는 것입니다.
#Embarked별 Fare의 평균
df.groupby(['Embarked'], as_index=False)['Fare'].mean()
##Embarked별 Fare의 중앙값
df.groupby(['Embarked'], as_index=False)['Fare'].median()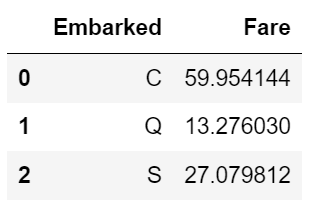
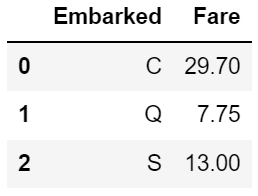
운임료에 대한 평균값, 중앙값 둘 다 확인해본 결과 C지역 탑승객들이 다른 지역보다 더 비싼 객실을 이용한 것으로 확인되고 있습니다. 확실히 C지역의 탑승객들이 다른 지역에 비해 더 부유한 것을 알 수 있습니다.
pclass_df = pd.DataFrame(df.groupby(['Embarked','Pclass'])['Pclass'].count())
embarked_df = pd.DataFrame(df.groupby(['Embarked'])['Pclass'].count())
ratio_df = ((pclass_df / embarked_df) * 100).round(2)
ratio_df.columns = ['Pclass 비율']
ratio_df한편, Embarked 지역별 Pclass 분포를 확인했을 때 절대적인 1등급 탑승객의 수는 S지역이 가장 많았지만 비율로 환산했을 때는 C지역이 제일 높았습니다. C지역 탑승객 중 무려 50%가 1등급칸을 이용한 것을 볼 수 있습니다. 지금까지의 분석을 종합해 보면 확실히 C지역의 탑승자들에 부유층이 많음을 확인할 수 있고 때문에 생존율이 높았다고 결론 지을 수 있을 듯 합니다. 물론, 탈출 과정에서 부유층이 더 우선순위에 있었는지 혹은 1등급 객실이 탈출 경로에 더 가까웠는지는 다른 자료를 통해 확인은 해보아야 할 것입니다. 하지만, 지금까지의 분석을 통해서 적어도 1등급칸을 이용한 승객이 살아남을 확률이 꽤 높았음을 충분히 유추할 수 있습니다.

'BACS > 정규세션' 카테고리의 다른 글
| [BACS] 정규 세션 2주차 Titanic 시각화 (2) (0) | 2022.11.04 |
|---|---|
| [BACS] 정규 세션 2주차 Titanic 시각화 (1) (0) | 2022.10.14 |
| [BACS] 정규 세션 1주차 (강원도 소방 데이터) (0) | 2022.09.30 |
| [BACS] 정규 세션 1주차 (Pandas 실습 - World2012) (0) | 2022.09.27 |
| [BACS] 정규 세션 1주차 정리 part1 (0) | 2022.09.25 |