Info) 정규세션 1주차 (강원도 소방 데이터)
Problem. 왼쪽의 원본 데이터를 가공하여 오른쪽 데이터 형태로 만들기

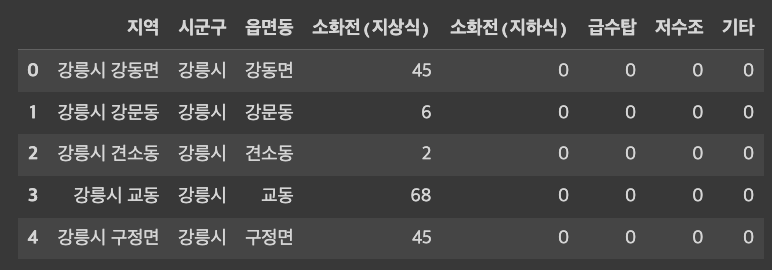
1. 데이터 불러오기
import pandas as pd
#관할서 센터별 소방용수 데이터
fire_df = pd.read_csv('./관할서 센터별 소방용수 데이터.csv')
#관할서 센터별 소방용수 데이터 feature설명
feature_df = pd.read_excel('./관할서 센터별 소방용수 데이터.xls')
#정답 파일: 강원도 지역별 소방용수시설 별 개수
answer_df = pd.read_excel('./강원도 지역별 소방용수시설 별 개수.xlsx')2. fire_df 확인 및 수정
2-1. fire_df 컬럼명 변경
#feature_df의 컬럼명 리스트로 가져오기
column_names = list(feature_df.columns)
#fire_df의 컬럼명에 추가하여 변경
fire_df.columns = column_names2-2. 결측치 확인 및 제거
#'소방용수구분명'의 결측치 확인
fire_df['소방용수구분명'].isna().sum()
#'소방용수구분명'이 null인 행 제거
fire_df.dropna(subset=['소방용수구분명'], axis=0, inplace=True)3. 파생변수 '지역' Column 만들기
#군구명과 동명을 합쳐 새로운 지역 컬럼 만들기
fire_df['지역'] = fire_df['구군명']+ ' ' + fire_df['동명']4. One Hot Encoding 적용
#fire_df에서 필요한 컬럼만 추출
fire_df = fire_df[['지역', '구군명', '동명', '소방용수구분명']]
#원핫 인코딩 적용하여 새로운 fire_df_new 생성
fire_df_new = pd.get_dummies(data = fire_df, columns = ['소방용수구분명'])5. Column 이름 재설정 및 순서 재배치
#fire_df_new의 컬럼명 재설정
fire_df_new.columns = ['지역', '시군구', '읍면동', '급수탑', '기타', '소화전(지상식)', '소화전(지하식)', '저수조']
#컬럼 순서 재설정
fire_df_new = fire_df_new[['지역', '시군구', '읍면동', '소화전(지상식)', '소화전(지하식)', '급수탑', '저수조', '기타']]6. groupby 통해 그룹별 집계
#groupby 통해 지역별 합계로 집계
fire_df_new = fire_df_new.groupby(['지역', '시군구', '읍면동']).sum()
#인덱스 초기화
fire_df_new.reset_index(inplace=True)
#최종 결과물 확인
fire_df_newcf) 다른 방식 (crosstab 활용)
cross_tab_prop = pd.crosstab(index=[fire_df['지역'], fire_df['구군명'], fire_df['동명']],
columns=fire_df['소방용수구분명'],
normalize= False,
margins = False)
cross_tab_prop.reset_index(inplace = True)
cross_tab_prop.columns = ['지역', '구군명', '동명', '소화전(지상식)', '소화전(지하식)', '급수탑', '저수조', '기타']
cross_tab_prop'BACS > 정규세션' 카테고리의 다른 글
| [BACS] 정규 세션 2주차 Titanic 시각화 (2) (0) | 2022.11.04 |
|---|---|
| [BACS] 정규 세션 2주차 Titanic 시각화 (1) (0) | 2022.10.14 |
| [BACS] 정규 세션 1주차 (Pandas 실습 - World2012) (0) | 2022.09.27 |
| [BACS] 정규 세션 1주차 정리 part2 (0) | 2022.09.26 |
| [BACS] 정규 세션 1주차 정리 part1 (0) | 2022.09.25 |