Warning) 아래 코드들은 버전이 바뀌어 정상적으로 작동되지 않을 수도 있습니다. 따로 버전을 명시하지 않았기 때문에 에러가 발생되면 조금씩 수정해 나가면서 사용하시길 바랍니다. 또한, 형편없는 저의 실력으로 코드들이 다소 비효율적일 수 있음을 미리 말씀드립니다. 우연히 이 글을 보게 되신 분들은 참고해주시기 바랍니다.
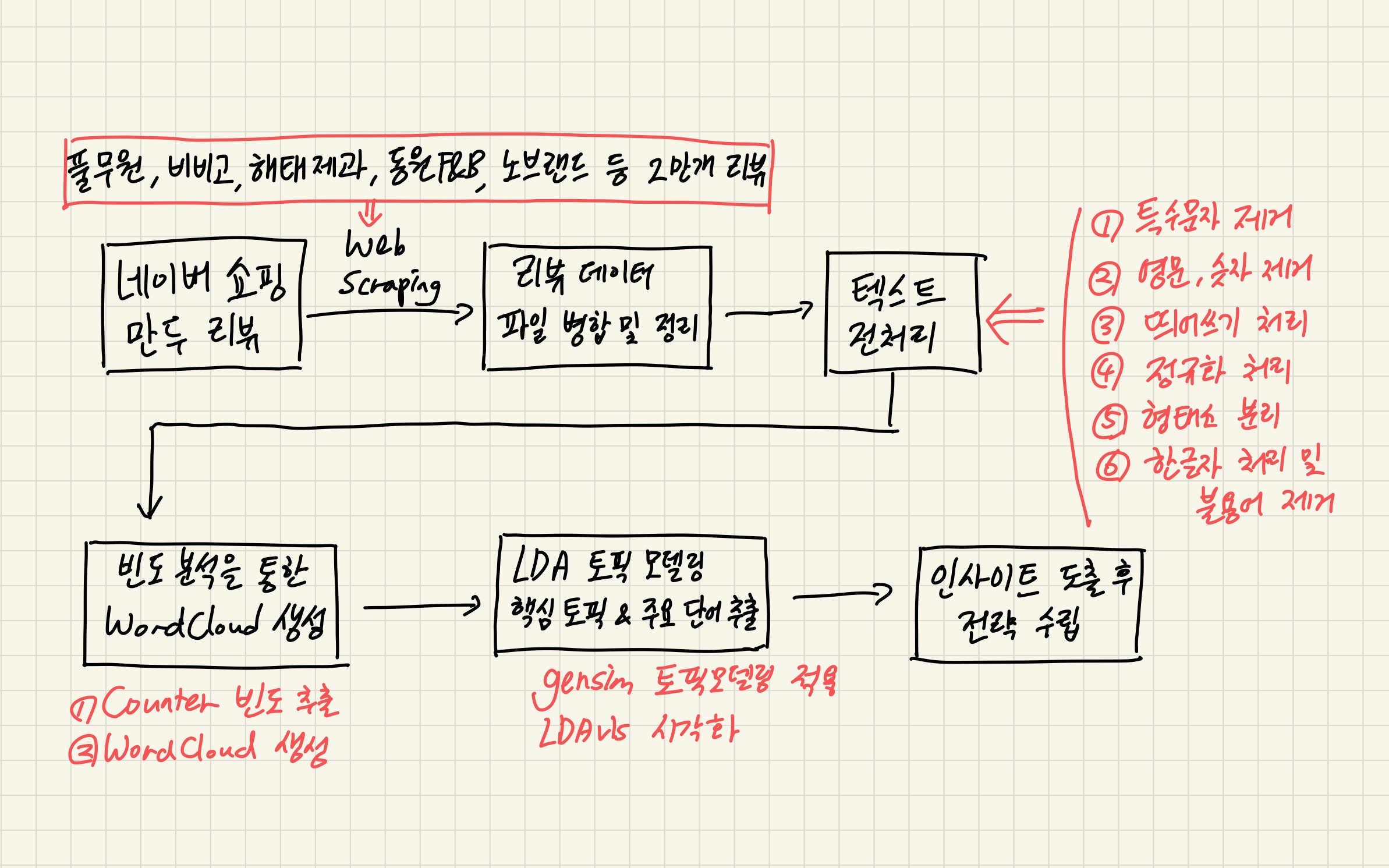
STEP 4. 빈도 분석을 위한 텍스트 전처리
STEP3에서는 이전를 날리는 일이 없도록 하기 위해 제품별 url을 하나의 리스트로 묶어 반복 실행하지 않고 일부러 따로 따로 독립적으로 수집하였습니다.
(1) 라이브러리 import 및 파일 불러오기
import pandas as pd
import re
df = pd.read_csv('/content/drive/MyDrive/Github/review-topic-modeling-project/output_file/all_review.csv')
df['Review']
8개 제품에d은 같기 때문에 2개의 코드만 가져왔고 이와 같은 방식을 8번 진행했다고 보시면 됩니다. 수집 결과 아래 사진과 같이 총 8개의 csv 파일이 만들어지게 됩니다.
(2) 특수문자 제거
df['Review'] = df['Review'].str.replace(pat=r'[^\w]', repl= r' ', regex=True) # replace all special symbols to space
df['Review'] = df['Review'].str.replace(pat=r'[\s\s+]', repl= r' ', regex=True) # replace multiple spaces with a single space
df
def extract_symbol(text):
text = text.str.replace(pat=r'[^\w]', repl= r' ', regex=True)
result = text.str.replace(pat=r'[\s\s+]', repl= r' ', regex=True)
return result(3) 한글 표현만 남기기
#한글 표현만 남기기
def extract_word(text):
hangul = re.compile('[^가-힣]')
result = hangul.sub(' ', text)
return resultprint("Before Extraction : ",df['Review'][17480])
print("After Extraction : ", extract_word(df['Review'][17480]))
print("Before Extraction : ",df['Review'][1494])
print("After Extraction : ", extract_word(df['Review'][1494]))
df['Review'] = df['Review'].apply(lambda x:extract_word(x))(4) 띄어쓰기 처리
pip install git+https://github.com/haven-jeon/PyKoSpacing.gitfrom pykospacing import Spacing
spacing = Spacing()
print("Before Fixing : ",df['Review'][324])
print("After Fixing : ", spacing(df['Review'][324]))
print("Before Fixing : ",df['Review'][14454])
print("After Fixing : ", spacing(df['Review'][14454]))
df['Review'] = df['Review'].apply(lambda x:spacing(x))
df['Review'][324]#띄어쓰기 처리
from pykospacing import Spacing
def extract_word(text):
spacing = Spacing()
result = text.apply(lambda x:spacing(x))(5) 형태소 분석
!pip install konlpy
from konlpy.tag import Okt
okt = Okt()
# 리뷰 텍스트 정규화 처리
df['Review'] = df['Review'].apply(lambda x: okt.normalize(x))
df['Review']
df.to_csv('/content/drive/MyDrive/Github/review-topic-modeling-project/output_file/processed_all_review.csv', index = False)지금까지 수집한 파일들은 output_file 폴더에 저장하였고 총 8개 파일이 있습니다. 파일들이 다 파편적으로 분리가 되어 있으면 텍스트 분석을 진행하는데 있어 번거로움이 발생합니다. 따라서, 파일들을 하나로 병합하도록 하겠습니다. 그리고 파일 병합을 진행하기 전에는 중복된 파일들이 있는지 확인하고 중복된 경우에는 제거하도록 하겠습니다.
words = " ".join(df['Review'].tolist())
words = okt.morphs(words, stem=True)
words
len(words)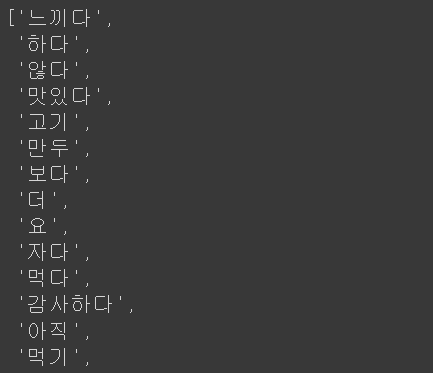
실 정확하게 스크래핑을

(6) 한글자 처리 및 불용어 제거
path = '/content/drive/MyDrive/Github/review-topic-modeling-project/output_file'
one_word = [x for x in words if len(x) == 1]
one_word_set = set(one_word)
print(one_word_set)
#특정 한글자를 제외한 나머지 한글자는 drop
remove_one_word = [x for x in words if len(x) > 1 or x in ['맛', '술', '양', '짱']]
len(remove_one_word)
#각 단어별 빈도수 확인
from collections import Counter
frequent_words = Counter(remove_one_word).most_common()
frequent_words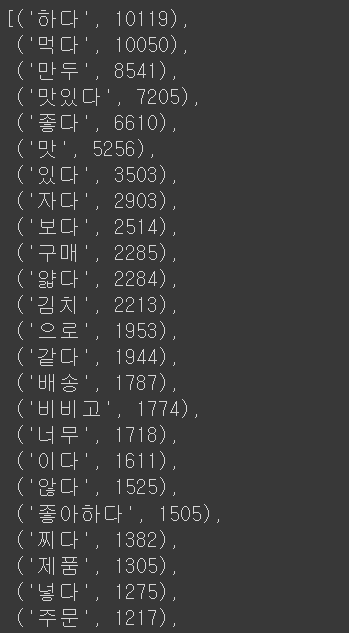
with open('/content/drive/MyDrive/Github/review-topic-modeling-project/stopwords.txt', encoding='cp949') as f:
stopwords_list = f.readlines()
stopwords = stopwords_list[0].split(",")
len(stopwords)
remove_stopwords = [x for x in remove_one_word if x not in stopwords]
len(remove_stopwords)
Counter(remove_stopwords).most_common()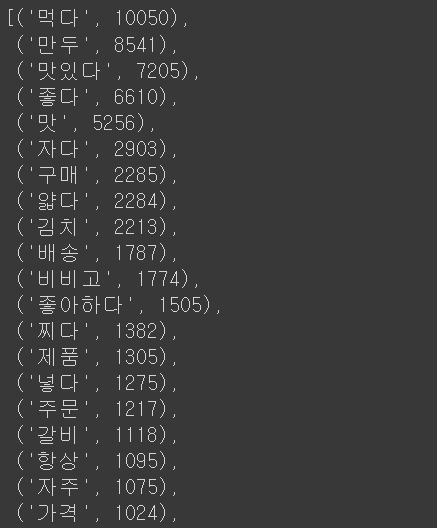
words_frequency = dict(Counter(remove_stopwords))
words_frequency(7) 빈출 키워드 워드 클라우드 생성
#!sudo apt-get install -y fonts-nanum
#!sudo fc-cache -fv
#!rm ~/.cache/matplotlib -rf
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# jupyter notebook 내 그래프를 바로 그리기 위한 설정
%matplotlib inline
# unicode minus를 사용하지 않기 위한 설정 (minus 깨짐현상 방지)
plt.rcParams['axes.unicode_minus'] = False
import matplotlib.pyplot as plt
plt.rc('font', family='NanumGothic')
df = pd.DataFrame(remove_stopwords, columns=['Word'])
wc = WordCloud(font_path='NanumGothic', colormap = 'summer', background_color = 'black', width=800, height=400, scale=2.0, max_font_size=250)
gen = wc.generate_from_frequencies(words_frequency)
plt.figure(figsize = (10, 8))
plt.style.use('seaborn-whitegrid')
plt.imshow(gen)
plt.grid(False)
plt.axis('off')
#wordcloud 이미지 저장
plt.savefig('/content/drive/MyDrive/Github/review-topic-modeling-project/output_file/wordcloud.png', dpi= 300)
후에는 중복된 리뷰 데이터들을 제거하겠습니다. 중복이 제거된 데이터프레임은 다시 새로운 파일로 저장하겠습니다.
중복 제거까지 진행한 결과 최종 수집된 데이터는 19445개로 당초 예상했던 2만개에는 조금 못 미치는 정도입니다. 중복된 내용 때문에 계획한 샘플 수를 충족시키지는 못했지만 결과에는 큰 영향을 주지 않을 것 같아 그냥 진행하도록 하겠습니다.
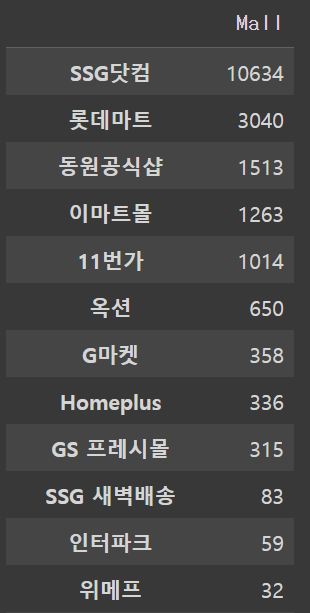
조금은 쓸데없는 과정이기는 하지만 쇼핑몰별로 수집된 리뷰 데이터의 수를 확인해보도록 하겠습니다. 앞서 프로젝트 계획 단계에서 편향되지 않은 분석 결과를 도출하기 위해 가능한 다양한 쇼핑몰에서의 리뷰를 가져오겠다고 말씀드린 적이 있습니다. 사실 리뷰의 출처가 되는 쇼핑몰이 다양할수록 리뷰 또한 다양하고 편향되지 않는다고 말할 수는 없습니다. 쇼핑몰과 리뷰 내용의 편향성은 상관관계가 높지 않을 것입니다. 하지만 한쪽 쇼핑몰의 리뷰만 가져올 경우에는 분명 해당 쇼핑몰만의 문제들이 분석 결과에 다소간 영향을 끼칠 수도 있는 있을 것입니다. 때문에 제 생각에는 쇼핑몰의 다양성을 유지하는 것이 그리 나쁜 선택은 아닌 것 같습니다.
아래 결과를 보면 이건 쫌... 이라는 생각이 드실 것 같습니다. 생각보다 쇼핑몰간 편차가 커 보입니다. SSG닷컴이 거의 전체 샘플 데이터의 절반 이상을 차지하고 있고 11번가까지 정도만 천단위 샘플이 수집되었고 나머지는 거의 미미한 수준입니다. 한편, 쿠팡이나 마켓컬리와 같이 최근 많은 매출을 기록하고 있는 쇼핑 플랫폼의 데이터가 없는 것이 아쉬움이 남습니다. 쿠팡 같은 경우는 네이버 쇼핑과 연동이 되지 않아 따로 수집해야 되는 것으로 보입니다. 여튼 분포 결과가 샘플의 균형을 맞추기에는 다소 부족한 부분이 있지만 실제로 결과물을 가져와 보아야 정확히 알 수 있을 듯 싶습니다.
다음 단계에서는 이번 프로젝트의 첫번째 핵심이라고 할 수 있는 텍스트 전처리를 진행하도록 하겠습니다. 전처리 수준에 따라 결과물의 내용이 달라질 수 있기 때문에 많은 심혈을 기울여야 될 것 입니다. 다음 스텝에서 뵙도록 하겠습니다.
'토이 프로젝트 > 토픽 모델링을 통한 냉동 만두 리뷰 분석' 카테고리의 다른 글
| [토이 프로젝트] 토픽 모델링을 통한 냉동 만두 리뷰 분석 (3) (0) | 2022.09.19 |
|---|---|
| [토이 프로젝트] 토픽 모델링을 통한 냉동 만두 리뷰 분석 (2) (0) | 2022.09.04 |
| [토이 프로젝트] 토픽 모델링을 통한 냉동 만두 리뷰 분석 (1) (0) | 2022.09.04 |