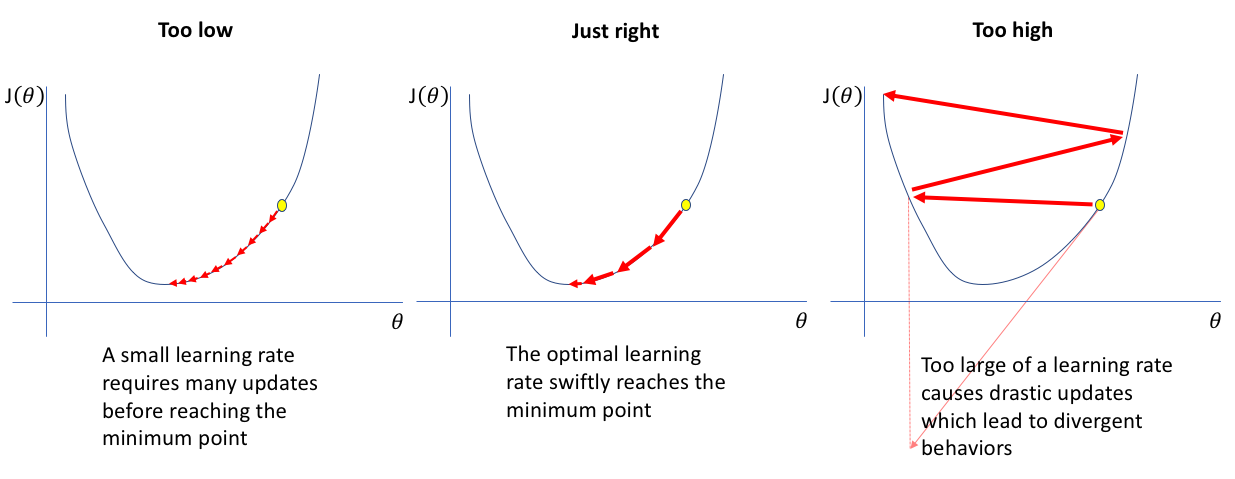
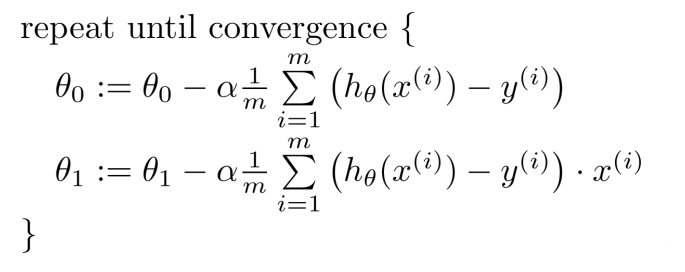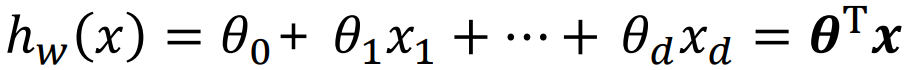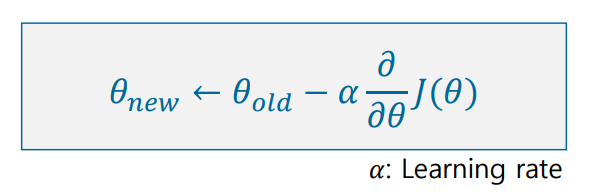Info) 아래 포스팅은 LGAimers에서 제공하는 AI 전문가 과정 중 이화여자대학교 강제원 교수님의 [지도학습(분류/회귀)] 강의에 대한 요약과 생각들을 정리한 것입니다. 정리된 내용들은 강의를 토대로 작성되었으나 수강자인 저의 이해도에 따라 일부 틀린 부분이 있을 수 있다는 점 알려드립니다. 잘못된 점이 발견될 시에는 즉각 수정하도록 하겠습니다. 또한, 강의의 모든 내용을 정리하기는 어렵기 때문에 인상깊었던 내용을 중심으로 정리하였습니다. 따라서, 설명의 맥락이 끊길 수도 있다는 점 양해 부탁드립니다.
0. Introduction
part4부터는 supervised learning의 다른 종류인 classification 문제에 대해 살펴보았습니다. 그 중 첫번째로 classification의 가장 기본적인 방법론인 linear classification을 공부하였는데 linear regression과 유사한 형태이기 때문에 학습하는데 어렵지는 않았습니다. 강의는 크게 3가지 부분을 전달하였습니다. 첫번째는 linear classification의 기본적인 원리와 로직, 두번째는 linear classification model이 적절한지를 판단할 수 있는 손실함수들, 마지막으로 multi classification 문제를 살펴보았습니다.
1. Linear Classification
linear classification model은 이전에 살펴본 regression을 위한 linear model과 그 형태가 유사합니다. 파라미터 w와 입력 feature인 x의 선형 결합으로 이루어진 형태로 w 벡터의 전치행렬(w.T)과 x 백터의 점곱으로 일반화할 수 있습니다. 다만, regression과의 차이는 model의 output이 연속형이 아닌 이산형이라는 점입니다. linear classification model은 sample들을 나누는 기준으로서 결정경계(decision boundary)라고 하며 초평면(hyperplane)이라고도 합니다. 가령, linear classification을 수행할 수 있는 hypothesis h(x)를 아래와 같이 정의한다면 이 선형 모델이 hyperplane이 됩니다.
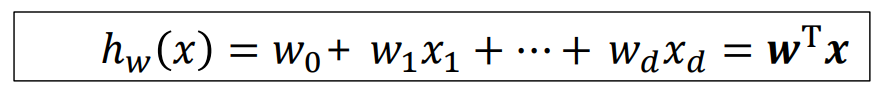
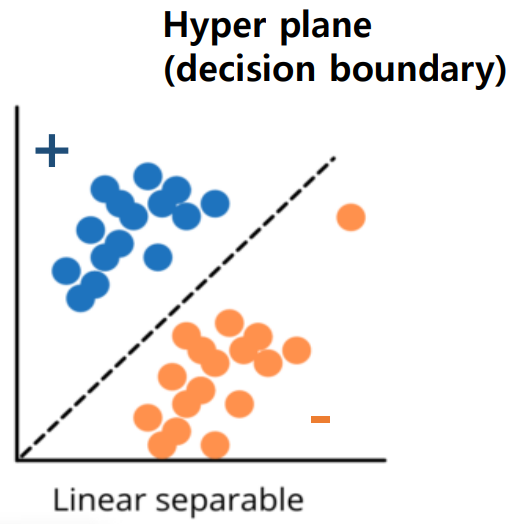
다음 그림을 보면 hyper plane을 기준으로 그 위쪽은 positive sample 그리고 아래 쪽은 negative sample들이 위치하고 있습니다. sample들을 매우 잘 구분한 hyper plane이라고 할 수 있습니다. 이 그림은 classification의 가장 단순한 가정을 보이고 있습니다. 오직 positive label과 negative label만 존재하는 이진분류(binary classification) 문제이고 linear classification model로도 충분히 분류 가능한 분포를 보이고 있습니다. 하지만 실제 현실에서는 linear model로 분류가 되지 않을 정도로 복잡한 경우가 많고 ouput 또한 3개 이상인 multi classification 문제들이 대다수입니다.

우리가 찾고자 하는 target function f를 approximate할 수 있는 hypothesis h는 다음과 같이 표현될 수 있습니다. 파라미터 w와 입력 x의 선형결합에 사인함수(signum function)를 적용한 형태입니다. 아래 그림에서 sign function 안의 summation 옆에 있는 w0는 bias 값(또는 offset)으로 가상의 x0(=1)을 곱해주는 것으로 하여 summation 안으로 넣어 정리할 수 있습니다. 이렇게 하면 w.T와 x의 곱으로 간단히 표현할 수 있고 이를 sign function의 input으로 넣어주게 됩니다. 오른쪽 sign function에 따라 w.Tx의 값이 양수이면 1(positive sample)을 반환하고 음수이면 -1(negative sample)을 반환하게 됩니다. 이런식으로 주어진 sample들을 각 label로 classification할 수 있게 됩니다.
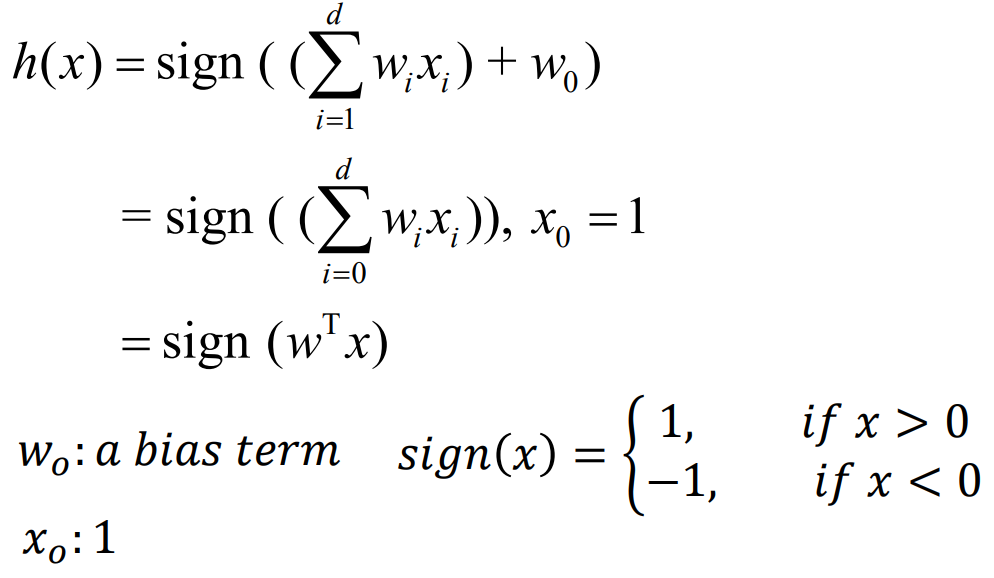

linear classification model은 하이퍼파라미터 w값에 따라 다른 선형 hyper plane이 그려지게 됩니다. 따라서 w값에 의해 잘못된 classification결과가 도출되기도 합니다. 따라서, model이 예측한 결과의 error를 계산하고 평가할 수 있는 metric들이 필요합니다. 이를 위해 score와 margin의 개념을 살펴보아야 하는데 'score'은 모델의 ouput으로서 예측 결과에 대해 얼마나 확신할 수 있는지를 보여주며, 'margin'은 그 예측값이 얼마나 correct한지 보여줍니다.
가령, 아래의 상황을 가정해볼 수 있을 것입니다. 입력 데이터 x, 타겟 레이블 y(1 또는 -1)이 주어졌을 때 결정경계 h(x)에 따라 4가지 경우의 수가 생길 수 있습니다. case1과 4는 margin값이 양수로서 예측값과 실제값이 같도록 올바르게 분류한 hyperplane입니다. 반면 case2와 3는 margin값이 음수로서 잘못 분류한 hyperplane입니다.
| case | score | y | margin(socre x y) | correctness |
| 1 | +1 | +1 | (+) | correct |
| 2 | -1 | +1 | (-) | not correct |
| 3 | +1 | -1 | (-) | not correct |
| 4 | -1 | -1 | (+) | correct |
2. Loss Function
2.1 Zero-one Loss
zero-one loss는 내부의 logic을 판별하여 맞으면 0을 틀리면 1을 출력하는 손실 함수입니다. 아래 왼쪽 식을 보면 model이 예측한 predicition값인 f(x)와 실제 target label인 y가 같지 않으면 1을 반환하게 됩니다. 위에서 살펴본 'score'과 'margin'의 개념을 적용해 보면 왼쪽의 식처럼 loss function을 일반화할 수 있습니다. 'score'값과 y값을 곱한 'margin'이 0보다 작거나 같으면 1을 반환하고 0보다 크면 0을 반환하는 것입니다. 즉, classification을 잘 수행하는 model일 경우 error가 0이며 반대로 classification을 잘 하지 못하는 부적합한 model은 error가 1이라고 간단히 이야기할 수 있습니다.
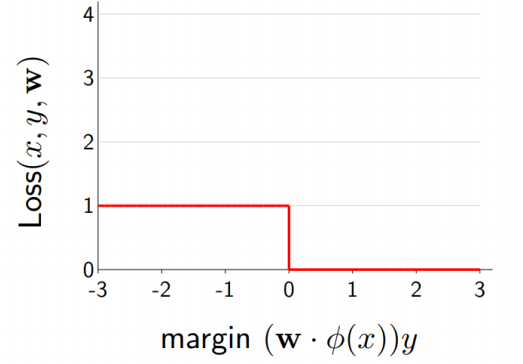
일반적으로 training의 과정은 loss function을 최소화하는 과정이라고 할 수 있습니다. 이를 위해 우리는 보통 gradient descent 방식을 적용하여 gradient가 0이 되는 지점을 향해 학습합니다. 하지만 지금의 zero-loss-function을 아래 오른쪽과 같이 미분을 했을 때 거의 대부분의 지점에서 gradient가 0이 됩니다. 따라서, model을 조정하는 학습의 과정을 거치지 못하게 됩니다. 따라서 이러한 문제를 해결하기 위해 다음에 살펴볼 Hinge Loss가 등장하게 됩니다.
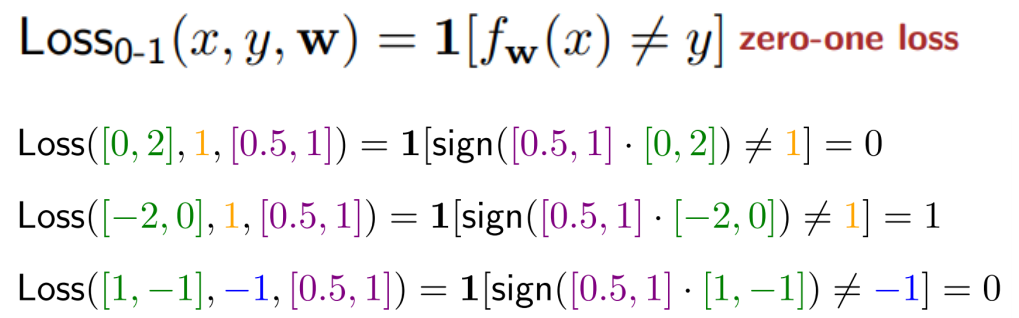
2.2 Hinge Loss

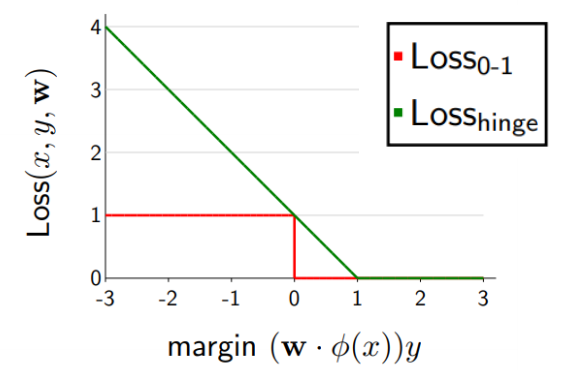
hinge loss는 (1- margin)값과 0 중 max값을 출력하는 loss function입니다. 앞서 살펴본 결과 우리는 model의 예측과 실제값이 같은 경우 즉, 정답인 경우에 'margin'은 1이 되고 틀린 경우 -1이 됨을 알고 있습니다. 그렇다면 hinge loss의 경우 이렇게 정리할 수 있을 것입니다. 정답을 맞춘 경우에 (1-margin)은 0보다 작기 때문에 hinge loss의 max 결과는 0을 출력하게 됩니다. 반대로 정답이 못 맞춘 경우에는 (1-margin)이 0보다 크기 때문에 hinge loss는 1-margin을 리턴하게 됩니다. 이를 그래프로 표현하게 되면 아래 그림의 초록색 선과 같을 것입니다.(그래프에서는 x축이 1-margin이 아닌 그냥 margin이기 때문에 1을 기준으로 값이 바뀌게 됩니다.) 이렇게 되면 우리는 gradient descent를 적용하여 학습할 수 있게 됩니다.
2.3 Cross-Entropy Loss
cross-entropy loss는 정보 이론에 기반한 loss function으로 여기서 cross-entropy는 불확실한 정보의 양을 토대로 최적화하는 작업이라고 할 수 있습니다. Kullback-Leibler 발산과 같은 원리를 가지며 위에서 살펴본 classification의 모델들이 내놓은 예측 label들이 얼만큼 틀렸는지를 entropy로서 확인하는 것입니다. 그에 따라 모델이 예측한 정보에 대한 probability mass function(pmf)의 차이를 비교하게 됩니다. binary classification의 경우 2개의 pmf를 비교하게 되는데 각각 p와 q라고 가정하였을 때 p와 q가 서로 유사하면 loss가 줄어들게 되고 반대로 p와 q가 다르면 loss값은 커지게 됩니다. 아래 식은 binary classification 문제에서 cross-entropy loss를 계산하는 식이 됩니다.
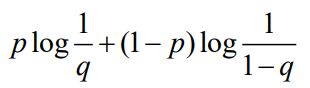
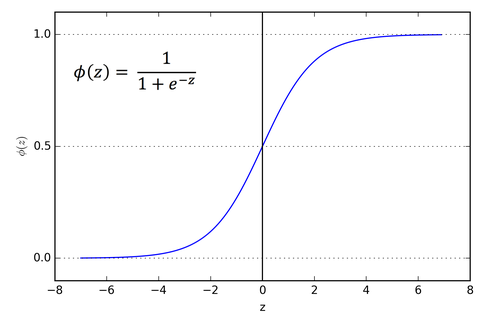
cross-entropy loss는 pmf 확률값을 사용하게 되는데 우리가 모델을 통해 계산하게 되는 score값은 확률이 아닌 실수값입니다. 따라서, cross entropy loss를 계산하기 위해 실수 score값을 확률값으로 mapping할 필요가 있습니다. 이때 사용할 수 있는 것이 로지스틱 모델 함수라고도 불리는 sigmoid함수입니다. sigmoid함수는 입력값을 0과 1사이의 값으로 출력하는데 도움을 줍니다. 아래 왼쪽은 sigmoid 함수의 그래프를 보여주고 있습니다. sigmoid 함수를 통해 오른쪽과 같이 class 0과 class 1에 대해서 각각의 확률값을 계산할 수 있게 됩니다.

아래 그림을 보면 cross-entropy loss를 더 간단히 이해할 수 있습니다. 왼쪽의 값들은 모델의 예측에 대한 확률의 분포입니다. 오른쪽은 실제 정답에 대한 확률의 분포입니다. 가령, onehot encoding으로 표현된 실재값이 [1, 0, 0]이라고 가정하고 예측값이 [1, 0, 0]인 경우 이때의 loss는 0됩니다. 하지만 [0, 1, 0], [0, 0, 1]과 같이 실재와는 전혀 다른 분류를 할 경우에는 무한대에 가까운 loss를 가지게 됩니다.
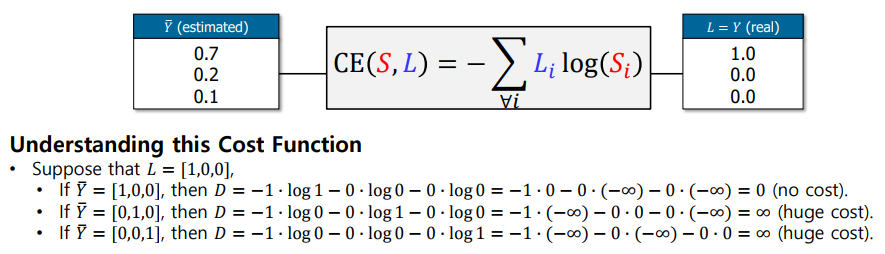
3. Multiclass Classification
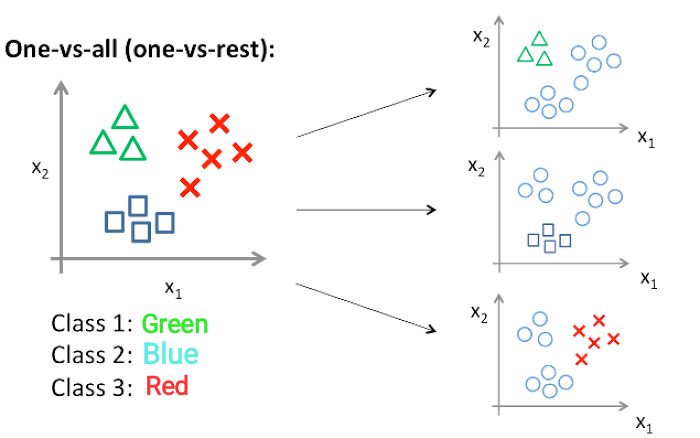
지금까지 살펴본 예시들은 이진분류(binaryclass Classification) 문제들입니다. 그러나 실제로는 많은 class들이 존재하는 multiclass classification 문제들이 다수를 이룹니다. multiclass classification을 python으로 구현하기는 너무 복잡하기에 일반적으로 binary classification을 확장하여 multiclass 문제를 해결하게 됩니다. 이를 one vs all 또는 one vs rest 방식이라고 합니다. scikit learn에서는 multiclass 문제를 binary classification 문제 여러개로 나누어 해결을 하게 됩니다.
출처: LGAimers / https://www.lgaimers.ai/
'LGAimers' 카테고리의 다른 글
| [지도학습] Part 5. Advanced Classification 정리 및 소감 (0) | 2022.07.26 |
|---|---|
| [자율주행과 레이더 센서의 이해] 정리 (0) | 2022.07.25 |
| [비지도학습] Part 1. 전통기계학습과 딥러닝에서의 비지도학습 정리 및 소감 (0) | 2022.07.20 |
| [지도학습] Part 3. Gradient Descent Algorithm 정리 및 소감 (0) | 2022.07.19 |
| [지도학습] Part 2. Linear Regresso 정리 및 소감 (0) | 2022.07.18 |