Warning) 아래 코드들은 Google Colab을 기반으로 작성된 것이기에 다른 환경에서는 정상적으로 작동이 안 될 수 있음을 알려드립니다. 또한, 형편없는 저의 실력으로 코드들이 다소 비효율적일 수 있음을 미리 말씀드립니다. 우연히 이 글을 보게 되신 분들은 참고해주시기 바랍니다.
STEP 2. 로튼 토마토 사이트에 있는 Critic리뷰 스크래핑
(1) Selenium 및 webdriver 설치
감성분석을 수행하기 하기 전 필요한 데이터(리뷰)들을 수집하는 스크래핑 과정을 보여드리겠습니다. 간략히 로직에 대해 설명드리면, 로튼 토마토 사이트 내 특정 영화 리뷰에 대한 URL을 입력하면 해당 영화 Critic 리뷰를 모두 긁어오는 것입니다. 보통 웹 스크래핑에서 BeautifulSoup과 Selenium이 양대산맥으로서 많이 사용되는 패키지들인데 지금은 Selenium을 사용하도록 하겠습니다. 앞서 STEP 1에서 설명드린 바와 같이 로튼 토마토에서는 모든 리뷰를 가져오기 위해 next 버튼을 누르며 20개 간격으로 리뷰를 스크래핑해야 하기 때문에 웹브라우저 조작이 가능한 Selenium이 더 편리하다고 할 수 있습니다.
우선 웹스크래핑을 위해 Selenium을 설치하도록 하겠습니다. (1) Selenium 설치 후, (2) 우분투 환경을 업데이트해주고 (3) chromium의 chromedriver을 설치해줍니다. (4) usr 디렉터리 안에 있는 chromedriver 폴더를 usr/bin 디렉터리로 복사해주고 나서 (6) '/usr/lib/chromium-browser/chromedriver' 폴더를 환경변수 지정해줍니다. 그러면 이 폴더 안에 있는 파이썬 파일들을 쉽게 import 할 수 있습니다.
!pip install Selenium #(1)
!apt-get update #(2)
!apt install chromium-chromedriver #(3)
!cp /usr/lib/chromium-browser/chromedriver /usr/bin #(4)
import sys #(5)
sys.path.insert(0, '/usr/lib/chromium-browser/chromedriver') #(6)(2) 필요한 라이브러리 import 및 chorme_options 설정
Selenium 설치와 환경설정을 완료했으면 필요한 라이브러리를 import하고 chrome_options를 미리 설정하도록 하겠습니다. chrome_options를 설정하는 이유는 웹 스크래핑을 수행할 때 웹 브라우저를 띄우지 않으면서 스크래핑을 진행하기 위해서입니다. 웹 브라우저 창을 띄우면서 스크래핑을 진행하면 스크래핑하는 창과 코드가 실행되는 창을 왔다 갔다 하도록 코드를 짜줘야 하기 때문에 더 복잡하고 비효율적이게 됩니다. 다소 설명이 이상한 것 같긴 한데... 여하튼 '--headless', '--no-sandbox' 등 옵션 변수들을 추가해주도록 하겠습니다.
import time
import pandas as pd
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException, ElementNotInteractableException
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')(3) page_click() 함수 만들기
다음으로는 page_click(), review_scraping() 함수를 만들도록 하겠습니다. 전자는 웹페이지 안에서 next 버튼을 눌러 다음 페이지로 이동하도록 하는 함수이고 후자는 리뷰를 긁어모으는 과정을 함수로 만든 것입니다. review_scraping()함수 안에서 page_click() 함수가 실행된다고 보시면 됩니다.
(※ page_click() 함수는 굳이 만들지 않고 review_scraping() 함수 안에서 직접 실행시키셔도 상관없습니다.)
page_click()에서 주의하실 점은 find_element를 통해 next 버튼에 해당하는 element를 찾아내어 click한 후에는 꼭 time.sleep()을 1,2초 정도 해주시기 바랍니다. 다음 페이지로 이동하는데 보통 1초 내외의 시간이 소요되는데 이 속도보다 더 빠르게 스크래핑을 시작하게 되면 NoSuchElementException 등의 에러가 발생할 수 있기 때문입니다.
def page_click(wd):
next_bt = wd.find_element(By.XPATH, '//*[@id="content"]/div/div/div/nav[1]/button[2]/span')
next_bt.click()
time.sleep(1)(4) review_scraping() 함수 만들기
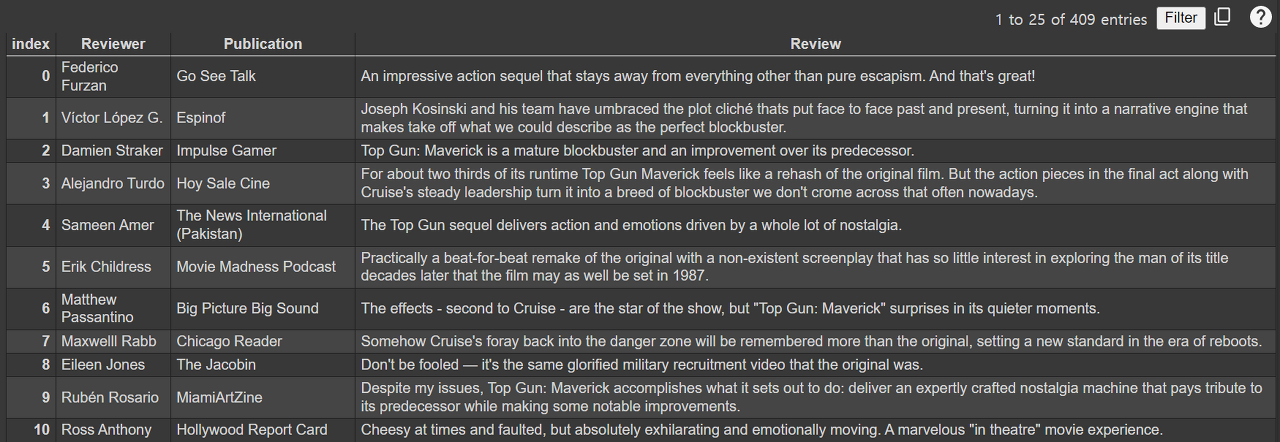
본격적으로 reveiw_scraping()함수를 만들어보도록 하겠습니다. webdriver 객체를 chrome으로 설정하여 생성합니다. 그리고 함수 인자로 받을 url값을 통해 로튼토마토 리뷰 페이지로 이동합니다. 스크래핑으로 통해 받을 내용은 'reviewer(리뷰 작성자)', 'publication(작성자가 속한 매체)', 'review(리뷰)' 총 3가지이며 최종 반환 값으로서 3가지 항목에 대한 내용을 pandas의 dataframe 형식으로 만들겠습니다. 스크래핑하는 과정과 dataframe으로 변환하는 과정은 아래 코드의 주석들을 통해 설명해놓았으니 참고하시기 바랍니다.
첫 페이지에서 20개의 리뷰를 모두 추출하여 dataframe으로 변환하였으면 앞서 만든 page_click() 함수를 호출하여 다음 페이지로 넘어갑니다. 그리고 while문 반복을 통해 20개의 리뷰를 추출하고 페이지를 넘어가는 과정을 반복합니다. 더 이상 페이지를 넘어갈 수 없다면(next 버튼이 존재하지 않는다면) 예외처리를 통해 반복을 break 하겠습니다. 리뷰가 정상적으로 스크래핑이 되고 있는지 육안으로 확인하기 위해 스크래핑 시작, 페이지 이동을 알리는 메시지들과 최종적으로 스크래핑을 진행한 영화의 리뷰가 총 몇 개 나왔는지 메시지를 출력하겠습니다.
def review_scraping(url):
# webdriver 객체를 chrome으로 하여 설정
wd = webdriver.Chrome('chromedriver', options = chrome_options)
wd.implicitly_wait(3)
# 해당 url로 이동
wd.get(url)
movie_review_df = pd.DataFrame() # 빈 move_review_df 생성
page_no = 1
print("[스크래핑 시작]")
# 매 페이지마다 반복적으로 리뷰를 스크래핑하기 위한 while문
while True:
try:
# 스크래핑할 3가지 항목에 대한 빈 리스트 생성
reviewer_list = []
publication_list = []
review_list = []
# find_elements를 통해 추출한 것들 중 text만 추출하여 빈 리스트에 추가
reviewers = wd.find_elements(By.CSS_SELECTOR, 'div.col-xs-8.critic-info > div.col-sm-17.col-xs-32.critic_name > a.unstyled.bold.articleLink')
reviewer_list += [reviewer.text for reviewer in reviewers]
#print(reviewer_list)
publications = wd.find_elements(By.CSS_SELECTOR, 'div.col-sm-17.col-xs-32.critic_name > a:nth-child(3) > em')
publication_list += [publication.text for publication in publications]
#print(publication_list)
reviews = wd.find_elements(By.CLASS_NAME, 'the_review')
review_list += [review.text for review in reviews]
#print(review_list)
# 20개의 리뷰를 스크래핑하여 만든 리스트들을 dataframe 형식으로 변환
new_movie_review_df = pd.DataFrame({'Reviewer': reviewer_list,
'Publication': publication_list,
'Review' : review_list})
movie_review_df = pd.concat([movie_review_df, new_movie_review_df], ignore_index = True)
# 해당 페이지의 리뷰 스크래핑이 완료되면 다음 페이지로 이동
page_click(wd)
page_no += 1
print('[다음 {}페이지로 이동]'.format(page_no)) # 페이지 이동할 때마다 메시지 출력
# 예외처리
except ElementNotInteractableException as ex:
print("[모든 스크래핑이 완료되었습니다.]")
break
except NoSuchElementException as ex:
print("[모든 스크래핑이 완료되었습니다.]")
break
# 더이상 넘어갈 페이지가 없어 스크래핑이 완료되면 아래 메시지 출력
mv_title = url.split('/')[-2].replace('_', ' ').title()
review_cnt = movie_review_df.shape[0]
print("\n영화 [{}]에 대한 {}개의 리뷰 스크래핑 완료".format(mv_title, review_cnt))
# 스크래핑한 결과물인 movie_review_df를 반환
return movie_review_df(5) review_scraping() 함수를 통해 스크래핑 진행
리뷰 스크래핑을 위한 모든 준비가 되었으니 본격적으로 리뷰를 가져와 보도록 하겠습니다. 최근 '탑건-메버릭'이라는 영화가 개봉되었는데 영화 '탑건'을 예시로 하여 스크래핑을 진행해보도록 하겠습니다. (리뷰 작성일 기준 총 409개의 리뷰가 있었습니다.)
url = 'https://www.rottentomatoes.com/m/top_gun_maverick/reviews'
movie_review_df = review_scraping(url)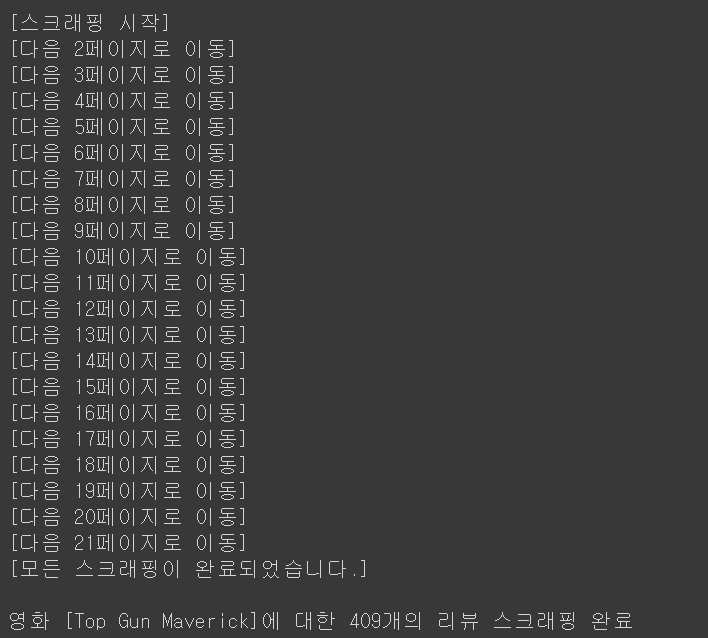
'토이 프로젝트 > 로튼 토마토 영화 리뷰 감성 분석' 카테고리의 다른 글
| [토이 프로젝트] 로튼 토마토 리뷰 감성 분석 (4) (0) | 2022.06.27 |
|---|---|
| [토이 프로젝트] 로튼 토마토 리뷰 감성 분석 (3) (0) | 2022.06.20 |
| [토이 프로젝트] 로튼 토마토 리뷰 감성 분석 (1) (0) | 2022.06.16 |