Intro) 데이터 분석을 할 때 저는 주로 Python을 이용하지만 가끔 R을 필요로 할 때가 있습니다. 아무래도 상황에 따라 R에서 코드가 더 간단할 때도 있고, 특히 고급통계 분석이나 시각화의 경우 육안으로 깔끔한 분석이 가능하기에 R이 편할 때도 있습니다. 그런데 R과 Python 간에는 미묘한 syntex 차이가 있어서 Python을 메인으로 사용하는 입장에서 오랜만에 R을 사용할 때면 헷갈리는 점들이 있습니다. 그래서 나중에 헷갈리는 부분들을 빠르게 찾아보기 위해 R의 기본적인 문법이나 자주 사용되는 라이브러리에 대해 앞으로 정리해보고자 합니다. 강필성 교수님의 [데이터 분석을 위한 프로그래밍 언어] 강의와 기타 자료들을 토대로 한 내용이지만 야매로 정리하다 보니 오류가 있을 수도 있습니다. 피드백 주시면 빠르게 수정하도록 하겠습니다.
1) 데이터 타입의 종류
R의 데이터 타입 중 Vector에 대해 간단히 살펴보도록 하겠습니다. Vector 타입에 대해 알아보기 전에 우선 데이터 타입에는 무엇이 있는지 살펴보겠습니다. 아래 그림처럼 scalar부터 다차원 배열의 tensor까지 여러 종류의 데이터 타입이 있지만 기초적인 데이터 분석에서는 vector와 matrix 그리고 dataframe이 가장 중요합니다.

데이터 타입을 구분하는 2가지 기준이 있습니다. 첫 번째는 변수(variables)들이 동질적(Homogeneous)인지 이질적(Heterogeneous)인지, 두 번째는 관측치(observation)가 한 개인지 여러 개인지입니다. 동질적(Homogeneous)이라는 것은 예를 들어 변수들이 모두 숫자형으로 형태가 모두 같아야 하는 것이고 이질적(Heterogeneous)이라는 것은 숫자형, 문자형, 명목형 변수 등 여러 형태가 섞여있는 것을 말합니다. 위 기준을 가지고 데이터 타입을 구분하면 아래 표와 같을 수 있습니다. 아래 표에서 조금 헷갈릴 수도 있는게 관측치가 1개이고 동질적이면 scalar 아닌가 생각될 수 있습니다. scalar라고 해도 되고 길이가 1인 Vector라고 할 수 있습니다.
2) 데이터 타입 - Vector(1)
R에서 는 '<-' 를 통해 A라고 선언한 변수에 c(15, 25, 35)와 같이 값의 결합을 넣어주면 벡터가 완성됩니다. Python에서 변수를 선언하고 값을 대입하는 방식과는 달라 조금은 생소하게 느껴집니다. 이때 주의할 점은 이전 [데이터 타입의 종류] 공부할 때 살펴 보았듯이 vector는 동질적(homogeneous)인 값으로 구성되어야 합니다. 따라서 B 벡터와 같이 숫자형과 문자형 값을 함께 주게 되면 R은 숫자인 값을 문자형으로 처리하여 'character'로 인식하게 됩니다.
# A와 B 벡터에 값 부여
A <- c(15,25,35)
B <- c(1, "A", 0.5)
# A벡터는 숫자형 B벡터는 문자형으로 인식
mode(A)
mode(B)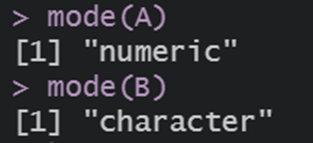
파이썬에서와 마찬가지로 R에서 인덱싱하는 방식은 비슷합니다. [1], [2:3] 와 같이 대괄호 안에 호출하고 싶은 값의 인덱스를 넣어주면 됩니다. 단, R에서는 다른 언어들과 달리 인덱스가 1부터 시작하게 됩니다. 이 점만 주의해주시면 됩니다. 그리고 A[c(2,3)]와 같이 concatenating 함수를 이용해 인덱싱할 수도 있습니다. 그리고 각 벡터 값에 이름을 부여하여 이름을 통해서도 인덱싱할 수도 있습니다. 아래 스크립트를 콘솔 창에 직접 입력하여 하나씩 확인해보시면 쉽게 이해하실 수 있을 것입니다.
# 벡터 값을 추출하는 방법(=파이썬의 인덱싱)
A[1]
A[2:3]
A[c(2,3)]
# 벡터에 이름 부여
names(A)
names(A) <- c("First", "Second", "Third")
# 인덱스 또는 이름을 통해 값 호출 가능
A[1]
A["First"]
'Python-R' 카테고리의 다른 글
| [R] 데이터 타입 - Matrix (0) | 2022.07.06 |
|---|---|
| [R] 데이터 타입 - List (0) | 2022.07.01 |